这个 Lab 里我们要手动构造一个 IP 请求,然后写一个把无序数据变成有序数据的 Reassembler.
Send an Internet datagram by hand
Reliability from unreliability 那节课的 notes(Lecture notes - Week 1 Day 2)里记录了一段示例代码,我们把它复制到 ip_raw.cc 然后改改就能发包了:
#include "address.hh"
#include "socket.hh"
using namespace std;
int main(int argc, char* argv[])
{
auto args = span( argv, argc );
string datagram;
datagram += static_cast<char>(0b0100'0101); // version and IHL
datagram += string( 7, 0 ); // rest of first two lines
datagram += static_cast<char>(64); // TTL
datagram += static_cast<char>(5); // proto
// checksum
datagram += static_cast<char>(0);
datagram += static_cast<char>(0);
// sender ip
datagram += static_cast<char>(10);
datagram += static_cast<char>(194);
datagram += static_cast<char>(218);
datagram += static_cast<char>(138);
// target ip
datagram += static_cast<char>(10);
datagram += static_cast<char>(195);
datagram += static_cast<char>(159);
datagram += static_cast<char>(100);
string art;
art += " ";
art += " /\\_____/\\ ";
art += " / o o \\ ";
art += " ( == ^ == ) ";
art += " ) ( ";
art += " ( ) ";
art += "( ( ) ( ) ) ";
art += "(__(__)___(__)_)";
art += " Lyraine Cat! ";
art += " ";
datagram += art;
RawSocket {}.send(datagram, Address(args[1], args[2]));
return 0;
}我在 WSL 上可以用上面的代码给室友的电脑发包,他能用 wireshark 监听到包,下图是 wireshark 截图:

接下来我们分析一下这段代码在做什么。我们被要求使用 Rawsocket 而非原始 socket 来发包,Raw Socket 一般工作在第三层网络层,所以我们要手动构造 IP 数据包。
我们回顾一下 IP header 的结构:
struct ip {
uint8 ip_vhl; // version << 4 | header length >> 2
uint8 ip_tos; // type of service
uint16 ip_len; // total length, including this IP header
uint16 ip_id; // identification
uint16 ip_off; // fragment offset field
uint8 ip_ttl; // time to live
uint8 ip_p; // protocol
uint16 ip_sum; // checksum, covers just IP header
uint32 ip_src, ip_dst;
};然后按格式填入数据就行。
Reassembler
接下来我们要实现一个重组器。重组器接受一个乱序的数据流,把他们组织成顺序并 push 到 ByteStream 中,这样读者就能读取顺序数据了,如下图所示:
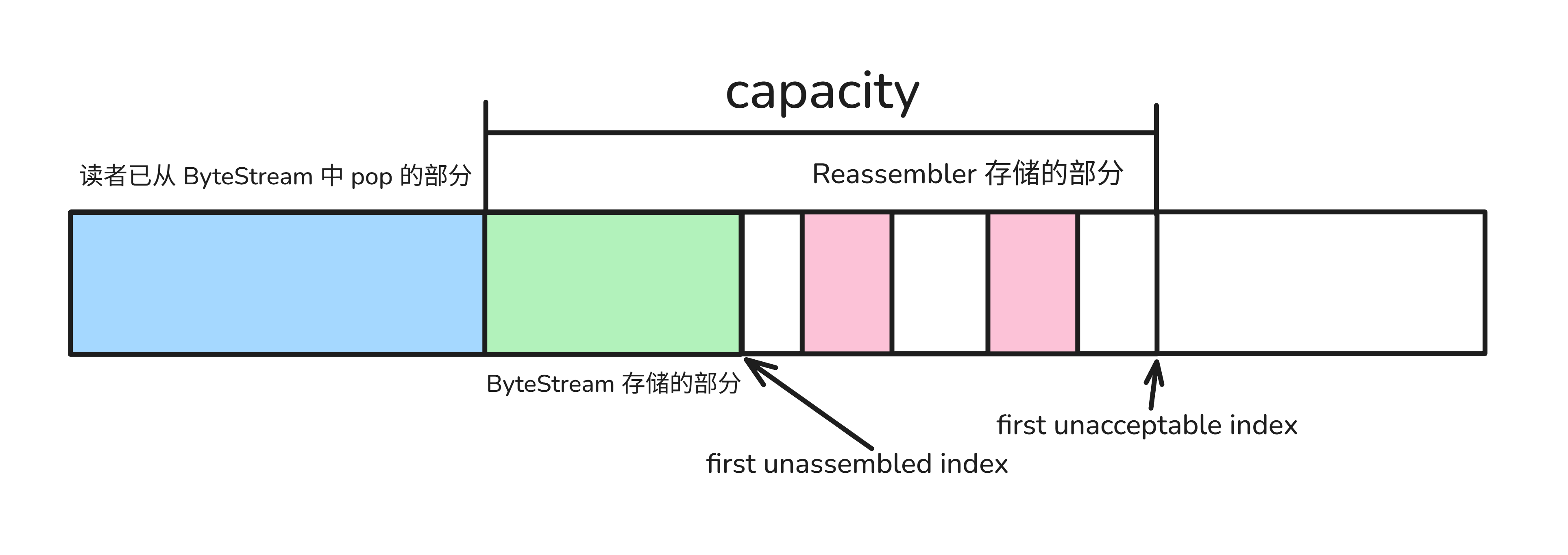
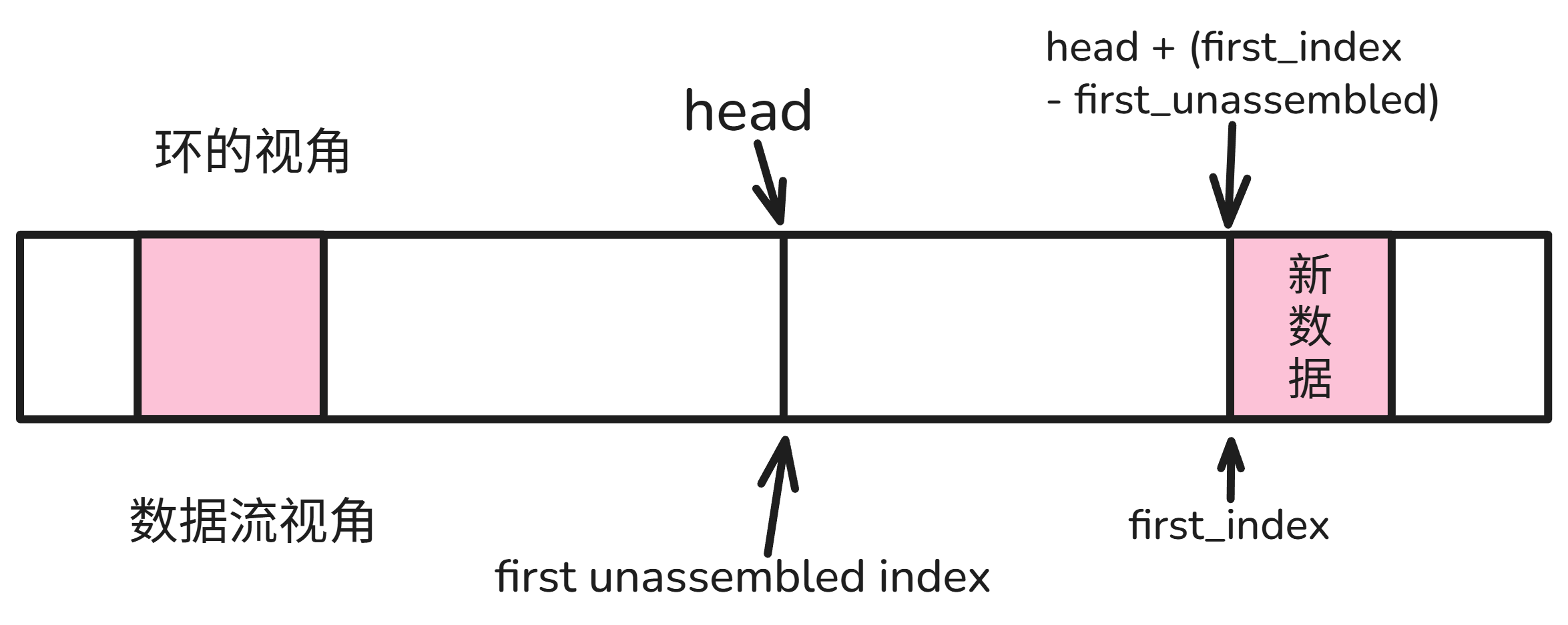
我们用环存储到达的数据,并维护一个 valid_ 数组以记录环的哪些位置是有效数据。对到达的新数据,一个朴素的处理思路如下,可以对照代码下面的图片来理解:
// 把数据存到环中
auto dst = ( head_ + first_index - first_unassembled_idx_ ) % ring_.size();
for ( uint64_t i = 0; i < data.size(); i++ ) {
ring_[( dst + i ) % ring_.size()] = data[i];
valid_[( dst + i ) % ring_.size()] = 1;
}
// 如果新数据填充了开头从而有了可以写入的连续数据, 写入 ByteStream
if ( first_index == first_unassembled_idx_ ) {
// 计算 written_len, 写入 ByteStream
// 更新 valid_, first_unassembled_idx, head_
}
上面的思路只能处理新数据的两端(first_index 和 first_indx + data.size)都在环内的情况,然而新数据的某一端可能在环外,这时我们就要裁剪数据,只把和环重叠的部分存入环中。
接下来我们给出完整代码,先放头文件:
class Reassembler
{
public:
explicit Reassembler( ByteStream&& output )
: output_( std::move( output ) )
, ring_( output_.writer().available_capacity() + 1 )
, valid_( output_.writer().available_capacity() + 1 )
{}
// ...
private:
ByteStream output_;
uint64_t head_ {}, first_unassembled_idx_ {}, eof_idx_ { UINT64_MAX };
std::vector<char> ring_;
std::vector<char> valid_; // use vector<char> instead of <bool> to improve performance然后是 insert 和 count_bytes_pending 的实现:
#include "reassembler.hh"
#include "debug.hh"
#include <algorithm>
using namespace std;
void Reassembler::insert( uint64_t first_index, string data, bool is_last_substring )
{
if ( output_.writer().is_closed() ) {
return;
}
if ( is_last_substring ) {
eof_idx_ = first_index + data.size();
}
// Cut overlap data
if ( first_index < first_unassembled_idx_ ) {
const uint64_t offset = first_unassembled_idx_ - first_index;
if ( offset >= data.size() ) {
return;
}
data = data.substr( offset );
first_index = first_unassembled_idx_;
}
// Copy data into ring
const uint64_t capacity = output_.writer().available_capacity();
if ( first_index >= first_unassembled_idx_ + capacity ) {
return;
}
const uint64_t cplen = std::min( data.size(), capacity - ( first_index - first_unassembled_idx_ ) );
const uint64_t dst = ( head_ + first_index - first_unassembled_idx_ ) % ring_.size();
const uint64_t len1 = std::min( cplen, ring_.size() - dst );
const uint64_t len2 = cplen - len1;
std::copy(
data.begin(), data.begin() + static_cast<int64_t>( len1 ), ring_.begin() + static_cast<int64_t>( dst ) );
std::copy(
data.begin() + static_cast<int64_t>( len1 ), data.begin() + static_cast<int64_t>( cplen ), ring_.begin() );
std::fill( valid_.begin() + static_cast<int64_t>( dst ), valid_.begin() + static_cast<int64_t>( dst + len1 ), 1 );
std::fill( valid_.begin(), valid_.begin() + static_cast<int64_t>( len2 ), 1 );
// Write into stream if possible
if ( first_index == first_unassembled_idx_ ) {
uint64_t written_len {};
for ( written_len = 0; written_len < capacity && valid_[( head_ + written_len ) % ring_.size()];
written_len++ ) {
valid_[( head_ + written_len ) % ring_.size()] = 0;
}
const uint64_t last = ( head_ + written_len ) % ring_.size();
// push [head_, last) or [head, size) + [0, last) into writer
if ( head_ <= last ) {
output_.writer().push( std::string( ring_.begin() + static_cast<int64_t>( head_ ),
ring_.begin() + static_cast<int64_t>( last ) ) );
} else {
output_.writer().push( std::string( ring_.begin() + static_cast<int64_t>( head_ ), ring_.end() ) );
output_.writer().push( std::string( ring_.begin(), ring_.begin() + static_cast<int64_t>( last ) ) );
}
first_unassembled_idx_ += written_len;
head_ = last;
// Close writer if all data have been writen into stream
if ( first_unassembled_idx_ == eof_idx_ ) {
output_.writer().close();
}
}
}
// How many bytes are stored in the Reassembler itself?
// This function is for testing only; don't add extra state to support it.
uint64_t Reassembler::count_bytes_pending() const
{
return std::ranges::count( valid_, 1 );
}最后跑出了 25Gbit/s 的结果,是文档说的“top-of-the-line”的两倍多🫠🫠
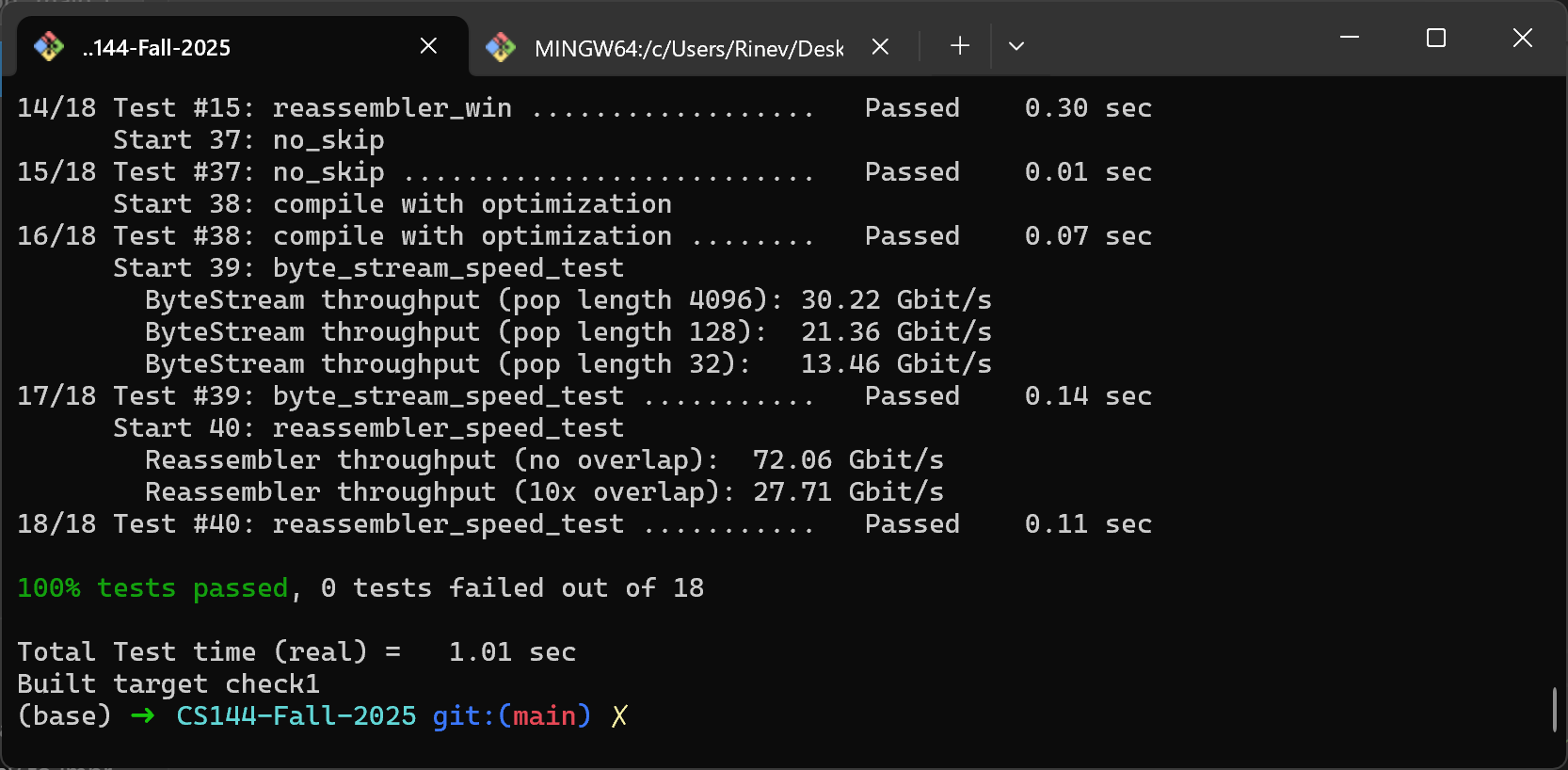
最后谈谈我优化性能的方法。我在优化时主要从少取模、少写 for 循环和少分支三方面考虑。
少取模和少写 for 循环是密切相关的。我们在用 for 循环遍历环时经常会对环的长度取模,典型例子就比如下面的代码:
for ( uint64_t i = 0; i < cplen; i++ ) { ring_[( dst + i ) % ring_.size()] = data[i]; }取模的速度很慢,手搓 for 循环来逐字节拷贝也比 std::copy 慢,所以我们可以用 std::copy 来代替这里的循环,得到:
const uint64_t len1 = std::min( cplen, ring_.size() - dst ); std::copy( data.begin(), data.begin() + len1, ring_.begin() + dst ); if (len1 < data.size()) { std::copy(data.begin() + len1, data.end(), ring_.begin()); }这能把 no overlap 的速度从 30Gbit/s 提升到 40Gbit/s,把 10x overlap 从 5Gbit/s 提升到 20Gbit/s
上面的效果已经很不错了,我们还能通过减少分支预测的开销来进一步优化性能:
const uint64_t len1 = std::min( cplen, ring_.size() - dst ); std::copy( data.begin(), data.begin() + len1, ring_.begin() + dst ); std::copy( data.begin() + len1, data.begin() + cplen, ring_.begin() );这能把 no overlap 的速度从 40Gbit/s 提升到 70Gbit/s,把 10x overlap 从 20Gbit/s 提升到 25Gbit/s