重走虚拟路
让我们尝试重新发明一遍虚拟内存。
使用虚拟地址的原因
想象一下我们只能用物理地址来写程序,我们写出了下面的东西:
1 | ; 假设目标机器是Intel 8080,内存地址为物理地址 |
这东西的可移植性显然很差!所以我们发明了“虚拟地址”。这样程序就能直接使用虚拟地址,而在程序执行时,虚拟地址被操作系统的MMU(Memory Management Unit)实时翻译成物理地址。
虚拟地址到物理地址的映射
这么看来,我们可以把 MMU 当作一个从虚拟地址空间到物理地址空间的映射,那我们自然要用一个数据结构来存储映射。
但怎么组织这个数据结构呢?用一个数组,然后每个虚拟地址对应一个物理地址?假设我们有 $M$ 个虚拟地址,我们就存一个长度为 $M$ 的数组?这样的话,这个数组就太大了。假设我们有 $k$ 个进程,按这个想法,我们就需要至少 $k\times M \times \text{sizeof(char *)}$ 大小的内存来存储这个数据结构。
我们选择把 $N$ 个连续的虚拟地址当作一个虚拟页,同时把 $N$ 个连续的物理地址当作一个物理页,这样对每个进程,我们就只要做物理页之间的映射,存储 $\frac{M}{N}$ 个项就好了。考虑到程序的局部性, 我们的这种选择是合理的。这样的一个数据结构就叫做一个页表。
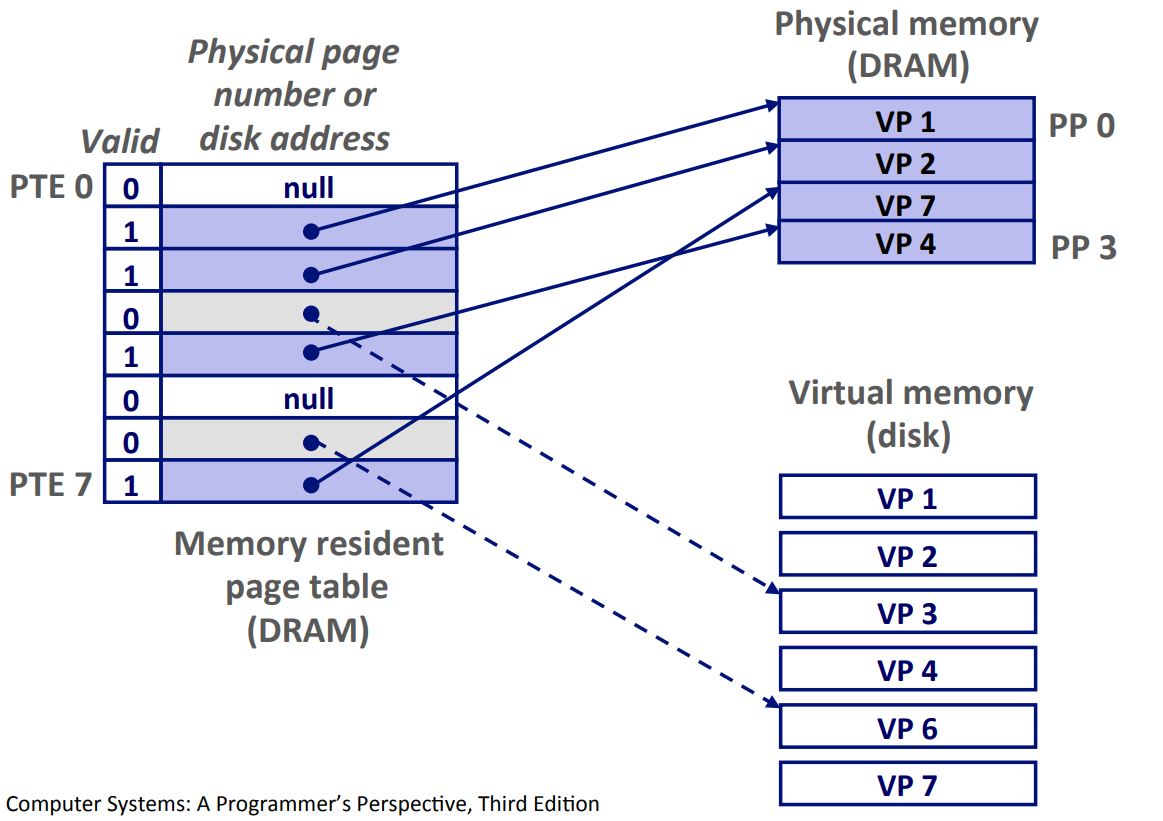
在下图的单级页表中,每一项都带有一个有效位(用于标记这个虚拟页对应的物理页是否在 DRAM 中)和对应物理页的开头物理地址(如果没有对应物理页,为 null)。
把虚拟地址翻译成物理地址的大致思路是根据虚拟地址找到页表中对应的项,从而找到对应的物理页,然后根据虚拟地址的最后几位确定具体的物理地址。(还记得吗,一个页由很多地址组成)
但这样的页表还是很大吧。我们总在进程被创建时就为他们分配了一个超大的页表,而实际上绝大多数程序都根本用不到那么多虚拟地址。所以,我们能不能动态地改变页表的大小,比如说,在程序请求某个虚拟地址,但它不在页表中时,再去增大页表?
所以我们进一步把页表分成多级,在需要的时候再去新增 level 较高的页表。
在这样的多级页表中,只有 level 最高的页表存储对应页的开头物理地址,而其他 level 的页表存储下一个级别的页表的开始地址。我们会在下一节详细讲解它的翻译过程。
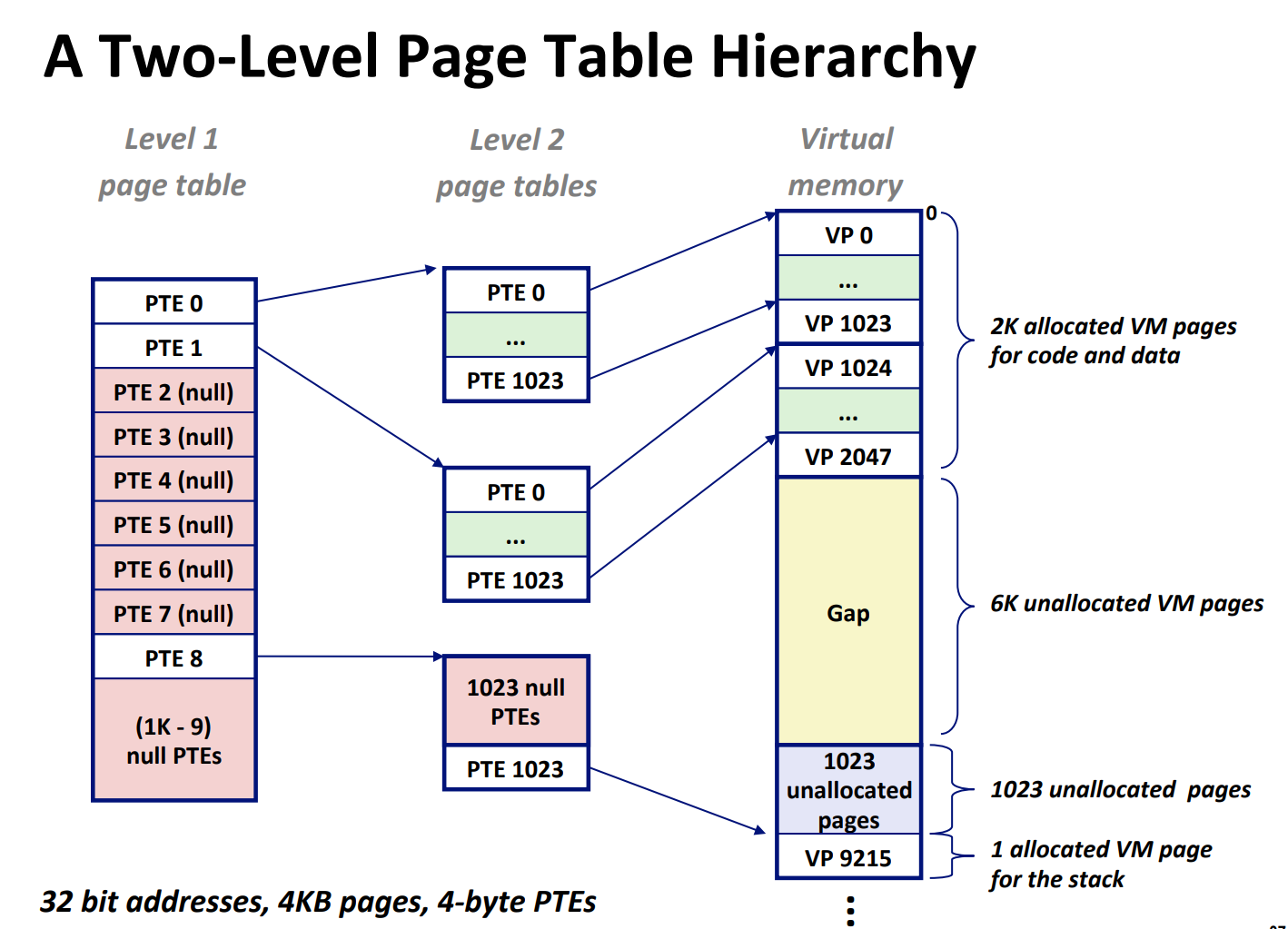
让我们总结一下,每个进程有自己的页表,在切换到某个进程时,操作系统会更新存储着页表地址的寄存器(在 RISC-Ⅴ 中是 satp 寄存器)。当进程需要访问某个虚拟地址时,MMU 会把虚拟地址翻译成物理地址,然后访问物理地址。
要特别强调的是,每个 level 可以有多个页表,我们可以把多级页表看作树状结构!
虚拟地址的翻译
我们已经知道了虚拟内存大致是怎样的了。那么 MMU 具体是怎么把虚拟地址翻译成物理地址的呢?我们这里讨论多级页表。
在多级页表中,只有 level 最高的页表存储对应页的开头物理地址,而其他 level 的页表存储下一个级别的页表的开始地址。
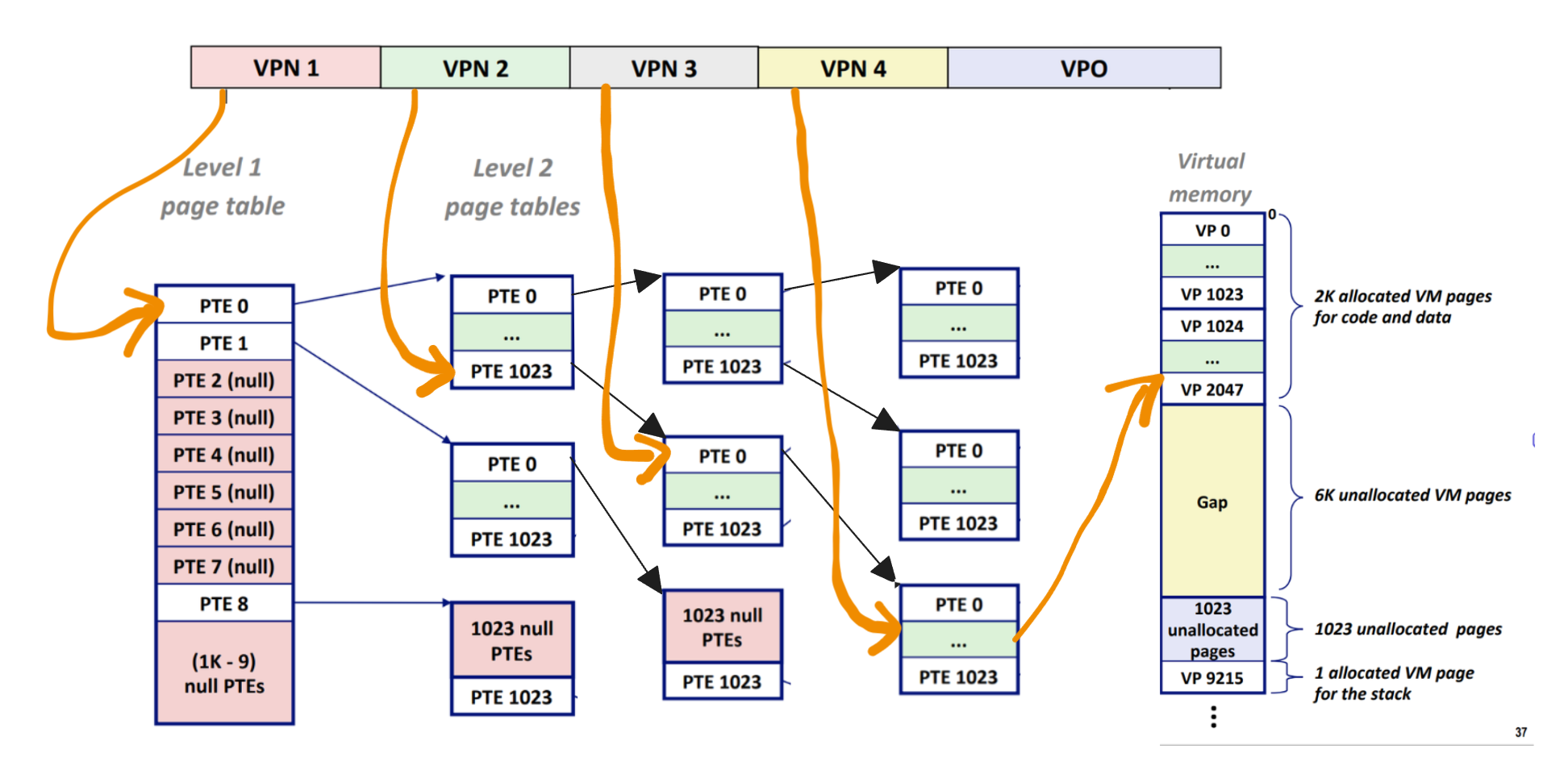
虚拟地址的前几位在翻译过程中会起到“页表索引”的作用,当我们到达了某个 level 的页表,我们会用它来确定我们具体需要这个页表的哪个项。而虚拟地址的最后几位是一个 offset,还记得吗,一个虚拟页和一个物理页对应,所以在找到了对应的物理页的开头地址后,我们要根据 offset 得到真正对应的物理地址。
VPN 是 virtual page number,VPO 是 virtual page offset,PTE 是 page table entry
![]()
我魔改了一下上图,希望这能让“每个 level 有多个页表”这件事显得更清晰。
优化
看起来多级页表在存储方面优化得不错,但速度呢?既然每个页表都放在不同的地址,那它不是要求多次访问不同地址吗?正是如此,所以我们用 TLB(Translation Lookaside Buffer)来缓存最近使用的页表项,来加快地址翻译。
动态内存分配
当我们调用 malloc 和 free 时究竟发生了什么?在做完 malloclab 以后,我们对此已经有了比较清晰的理解。
malloc
调用 malloc 时,我们在寻找足够大的空闲内存块来提供给用户,如果不够大就扩容。在“寻找”的过程中,我们有很多种策略可以选,这就是 placement policy,包括但不限于 first fit、next fit、best fit.
而在找到空闲块以后,有时空闲块可能比用户的需求大很多,这时就要想想要不要切割空闲块,这就是 splitting policy。
free
调用 free 时,我们简单地把一个已分配内存块标记为空闲。但空闲之后又要决定是否把它和相邻的空闲块合并,这就是 coalescing policy。
块的结构
之前提到,malloc 是在找空闲块,但什么是“块”呢?块的数据结构也有很多种可以选,不过一般来说,每个块都至少会有 size 和 is_alloc 标记。
举个例子,使用显式链表策略时,我们的堆大概长这样:
