15213 里没讲第四章,我看了下感觉太硬件了于是就跳过了。我们从第五章继续——
一些常见的优化手段我们就不详细说了,简单提一下有这些:
- 用代码剖析程序找到性能瓶颈
- 选好的算法
- 外提循环不变式
- 减少不必要的内存读写
循环展开技巧性太强,牺牲了可读性,而且说实话性能也没好太多,所以也不详谈。而且大多数编译器在把优化等级设得比较高时会自动做循环展开。
我们主要聊聊——编译器的局限;用 CPE 表示程序性能;指令级并行。
编译器的局限性
编译器对程序只使用安全的优化,因此有些我们脑补编译器会优化的东西实际上不会被优化。
1 | void add1(long *x1, long *x2) { |
乍一看这两个函数功能相同,且下面那种读写内存次数更少,或许我们会期望编译器把上面的版本优化成下面的版本。
可其实两者功能并不完全相同。考虑两个指针指向同一个对象的情况。
因此,要很仔细才能写出编译器能顺利优化的代码。
用 CPE 表示程序性能
CPE 即 Cycles Per Element,计算方法如下:
CPE = Total Cycles / Number of Elements,即总周期数 / 元素数量。
实际的 CPE 值很难仅通过代码分析准确预测,需要在特定硬件、编译器配置下通过实际测试获得准确值。一般来说,我们通过性能分析工具来得到总周期数,然后根据任务得出其元素数量,从而算出 CPE。
指令级并行
现代处理器并不是顺序执行指令的,顺序执行只是一种抽象。指令执行的顺序不一定要与它们在机器级程序中的顺序一致。这让我们实现了指令级并行。
这里的内容太多太硬核了,我也没理解,就只讲讲指令级并行的大体概念和流水线吧。
大体来说,处理器会分析程序里每条指令的依赖关系,从而并行执行没有依赖关系的指令。
例子:
假设我们有指令序列:
1 | 1. mov eax, [mem1] # 从内存加载数据到eax |
依赖关系图:
1 | 指令1 指令2 |
这时我们可能就会并行执行指令 1 和指令 2.
流水线(Pipeline)
流水线将单条指令的执行阶段(取指、解码、执行、访存、写回)拆分成多个步骤,每个步骤由不同的硬件单元处理,从而可以同时处理多条处于不同步骤的指令。例如,一个典型的浮点加法器包含三个阶段:一个阶段处理指数值,一个阶段将小数相加,另一个阶段对结果进行舍人。这种技术增加了吞吐量(Throughput),但单个指令的执行延迟并不会减少。
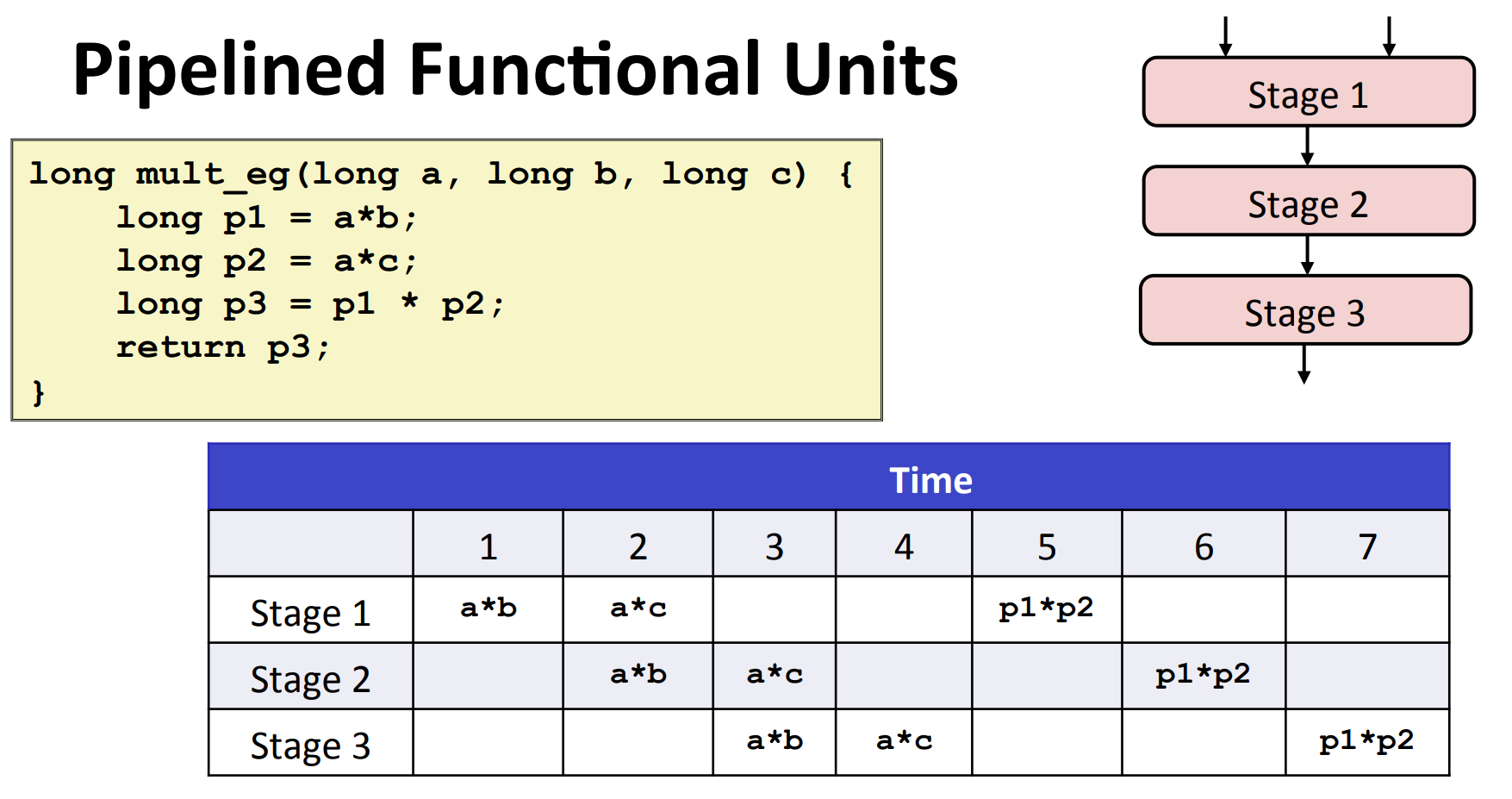
数据流图
我们可以通过程序的数据流图来粗糙地分析程序的指令级并行程度。这里举一个例子应该就足够了。假设我们想算 $\sum_{k=0}^{n}a_kx^k$,下面有两种算法:
在 poly 中,我们共做了 n 次加法,2n 次乘法
1 | double poly(double a[], double x, long degree) |
在 polyh 中,我们共做了 n 次加法,n 次乘法
1 | /* Apply Horner's method */ |
然而实际上 poly 速度更快,为什么呢?因为 poly 有更好的指令级并行度。
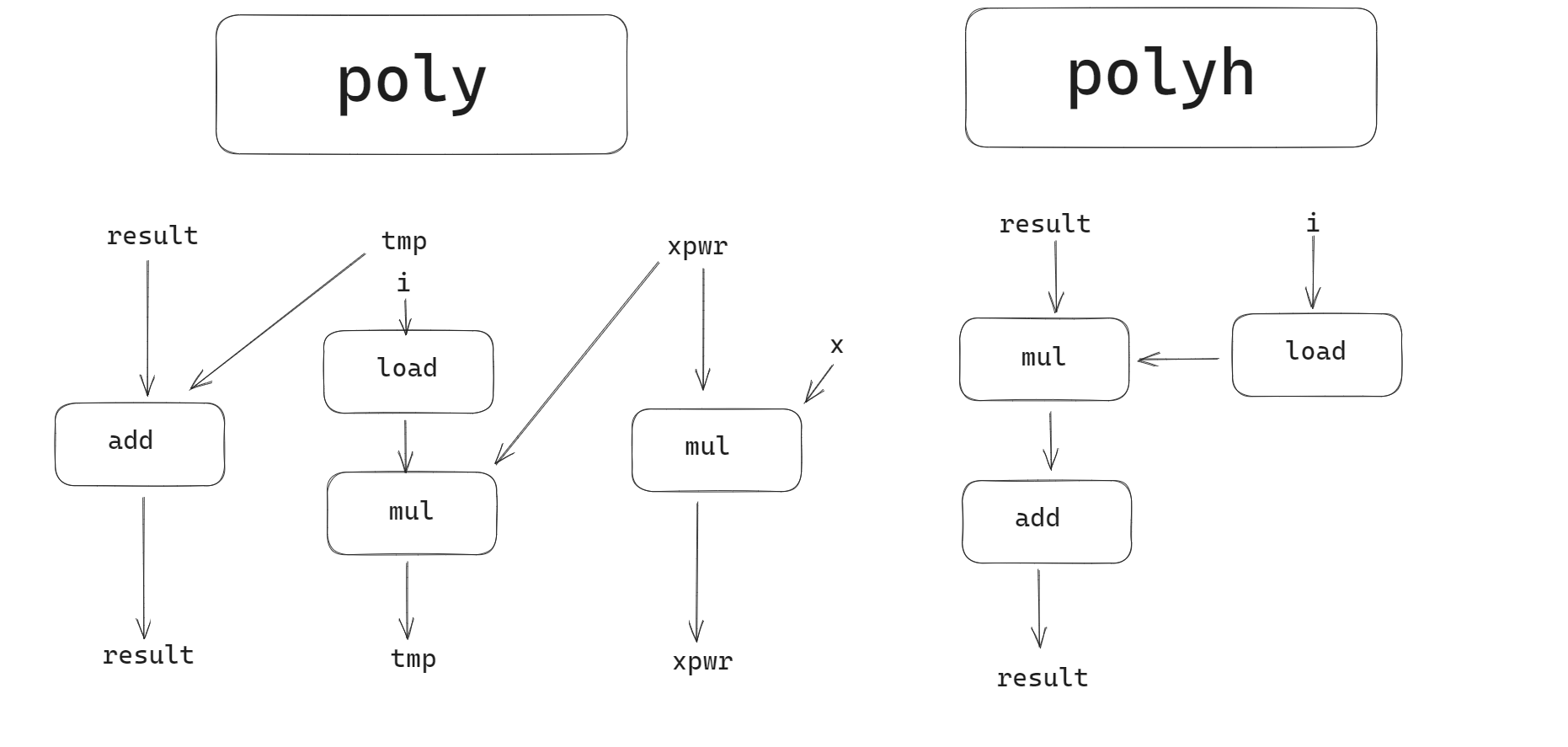
poly 的关键路径是 mul,polyh 的关键路径则是 mul → add.
实践
之前做 leetcode 还遇到了一则趣事(3356. Zero Array TransformationⅡ)
那题的解法里需要构造这样的函数:
1 | bool iskZeroArray(vector<int> &nums, vector<vector<int>> &queries, int k) { |
在 iskZeroArray 的第一个 for 循环中, 我写的原本是
1 | vector<int> query = queries[i]; |
但是这样的程序耗时 1000 ms. 换成
1 | int l = queries[i][0]; |
后,50ms. 两者甚至都是 O(N)的,前者之所以如此慢应该是因为不断分配内存给 query 吧.