汇编简介
CSAPP 教的是 x86-64 汇编语言,使用的是 AT&T 语法风格。
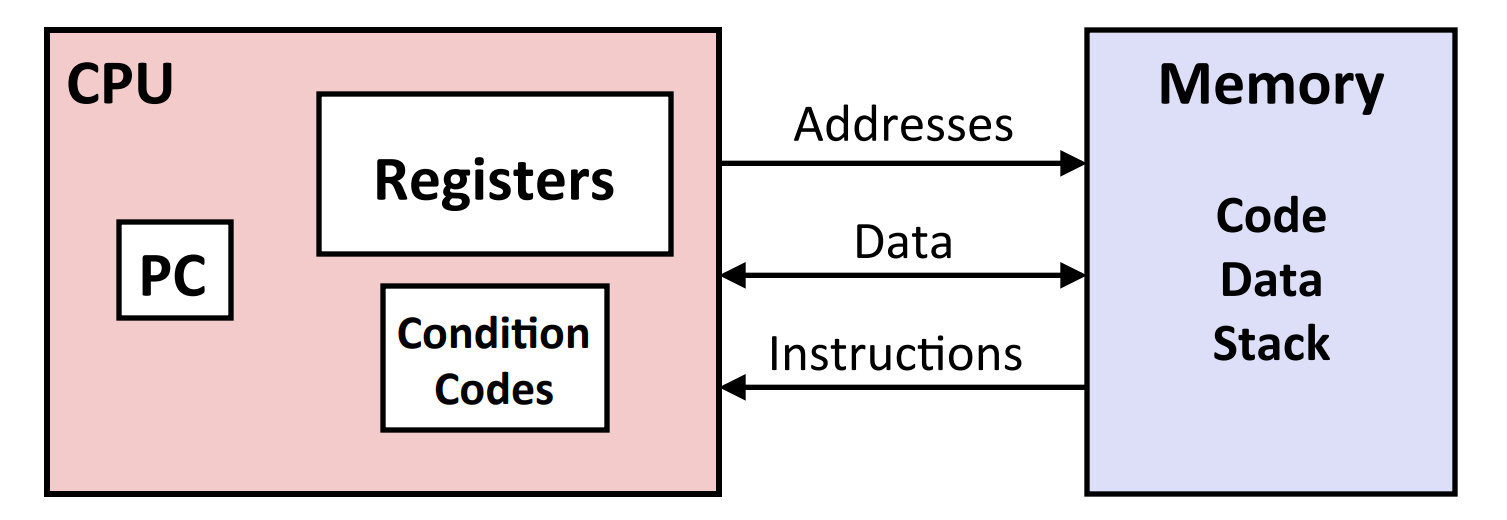
下图概述了程序的工作方式,即从内存中读取指令,CPU 根据指令在寄存器上执行操作来修改内存里的数据:
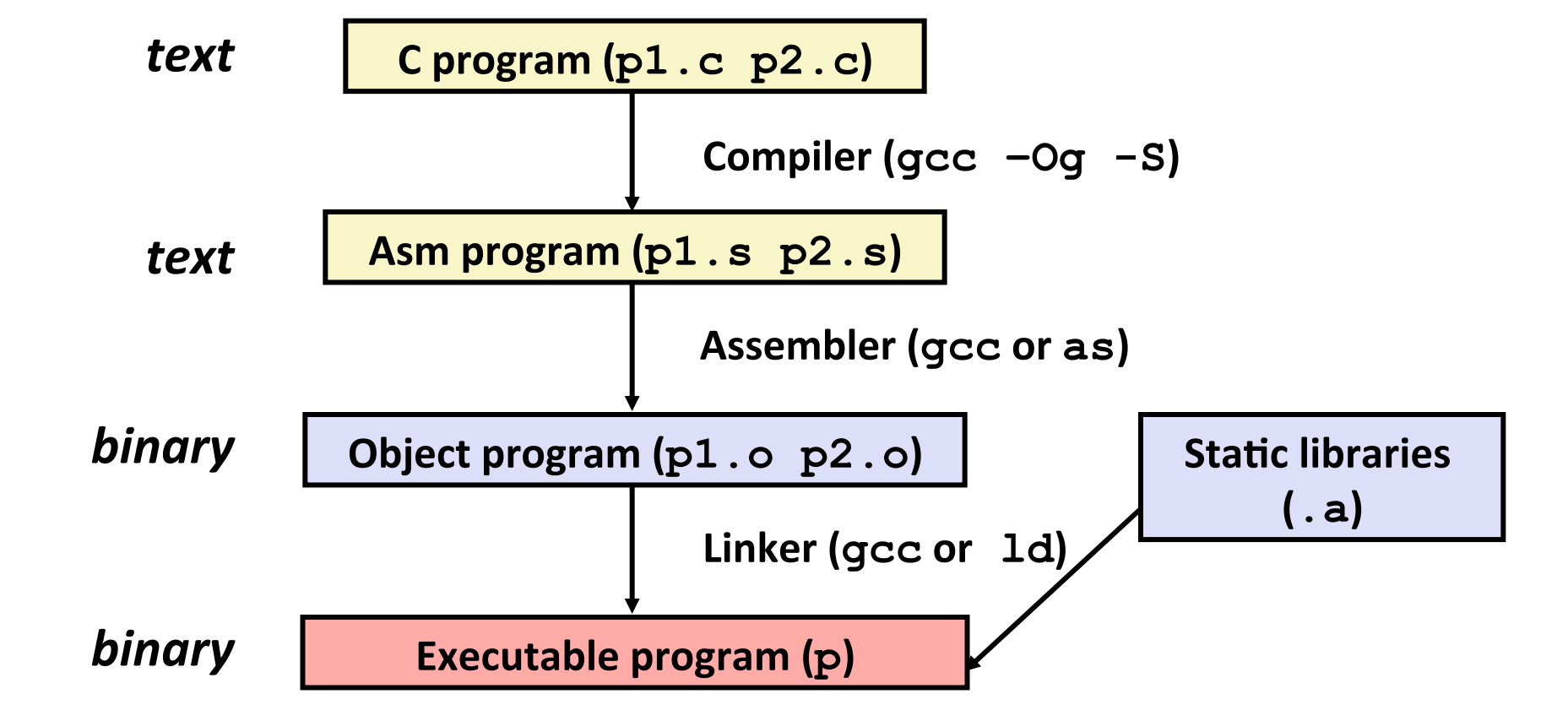
下图描述了借助 gcc 进行编译的过程,其中 .s 就是汇编文件:
一些汇编指令示例:
movq 7(%rdx, %rsi, 2), %rax 表示把 2 * %rsi + %rdx + 7 指向的地址的值复制到 %rax 中
leaq 7(%rdx, %rsi, 2), %rax 表示把 2 * %rsi + %rdx + 7 复制到 %rax 中,leaq 常被编译器用来做一些聪明的快速计算,不过 leaq 的第三个项只能是 1, 2, 4, 8.
salq $n, %rax 表示把 %rax 中的值左移 n 位 (sal 是 shift arithmetic left 的缩写)
imulq %rdx, %rax 表示把 %rdx 中的值与 %rax 中的值相乘,结果存入 %rax (有符号整数乘法)
操作很多,我们不再列举更多,随便找个书查一查就好。
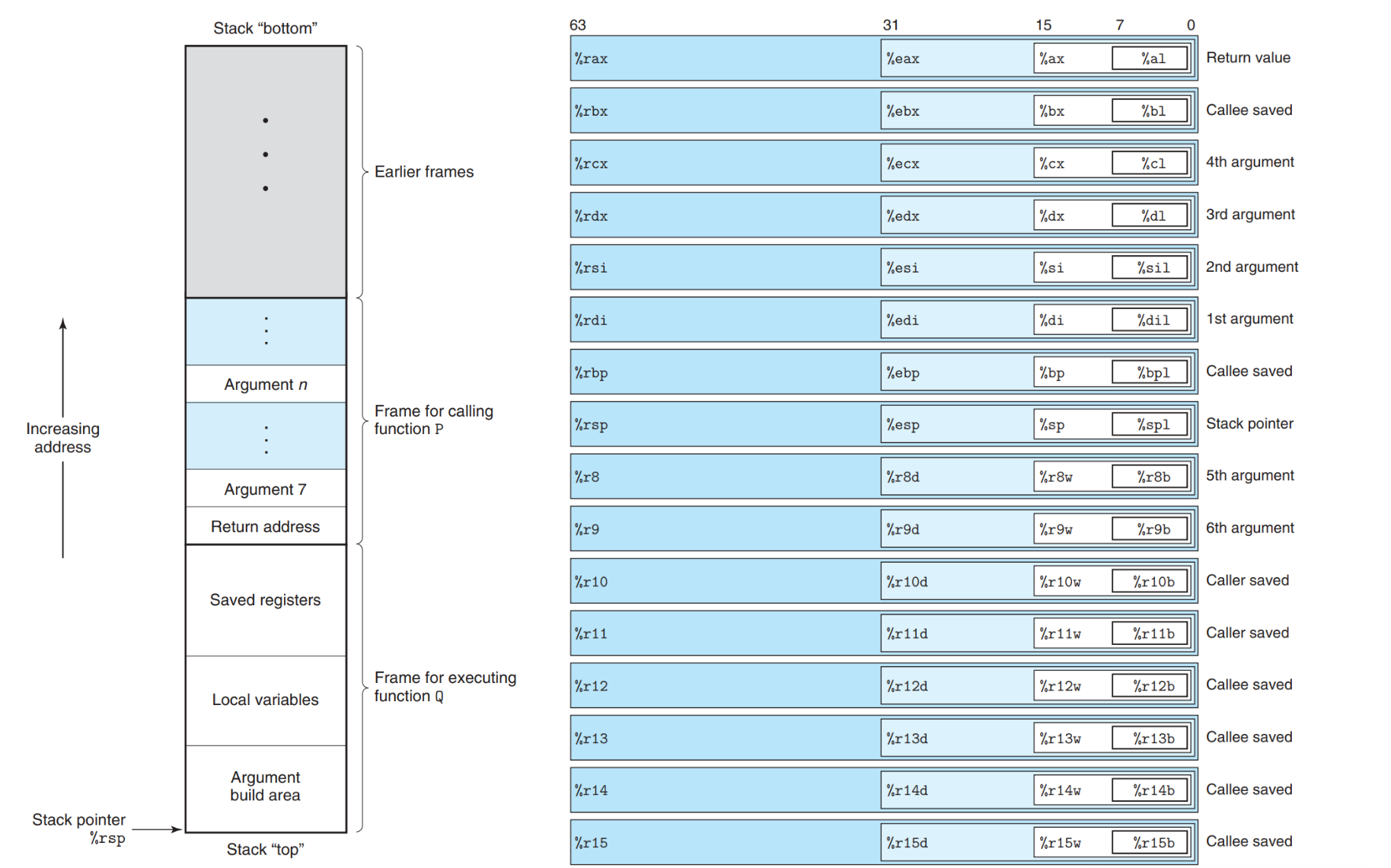
我们可以注意到这些操作都以 ‘q’ 结尾,那如果我不喜欢 ‘q’,我可以用 ‘r’ 结尾吗?不行,因为这里的 ‘q’ 实际上是在指定操作的大小。还记得寄存器长什么样吗:

| 后缀 | 全称 | 大小(字节) | 位数 | 指令示例 | 描述 |
|---|---|---|---|---|---|
b |
byte | 1 | 8 位 | movb |
移动单字节(8 位)数据 |
w |
word | 2 | 16 位 | movw |
移动字(16 位)数据 |
l |
long | 4 | 32 位 | movl |
移动双字(32 位)数据 |
q |
quadword | 8 | 64 位 | movq |
移动四字(64 位)数据 |
我们也有 pushq 和 popq 之类的和栈相关的操作。栈是什么?请看下集——函数和栈。(在“控制”这一节后面)
控制
我已经会加减乘除了,那你能教教我怎么写条件(if)和循环(for, while)吗?
乐意效劳。😎
if,while,do-while
无论是条件还是循环,我们都在做两件事——判断条件是否满足和根据条件跳到某个地方执行语句。
让我们先来看看汇编里的一个典型的 do-while 循环:
1 | long fact_do(long n) |
在这里,我们通过“cmpq”和“jg”来判断条件是否满足,通过“jg”来跳转以执行循环。那么,cmpq 实际上是在做什么呢?
在汇编中,我们有几个特殊的标志寄存器 CF、ZF、SF、OF 来记录最近的操作是否产生了 unsigned 的溢出、产生 0、产生负数、产生了补码溢出。cmp 和 test 两个指令假装执行减法和按位与并修改这些标志寄存器。
在上面的代码中,cmpq $1, %rdi 就是在假装做 %rdi - 1,并根据计算结果修改标志寄存器。而 jg 则根据标志寄存器的值来进行跳转。jg 的效果是,如果 ~(SF ^ OF) & ~ZF 为真,就进行跳转。
jg 的跳转条件看起来很复杂,但它和 cmpq x, y 联动的效果是——如果 y > x,跳转,因此它叫做 jg.
下表是 CMP 和 TEST 的概述:
| Instruction | Based on | Description |
|---|---|---|
| CMP S₁, S₂ | S₂ - S₁ | Compare |
| TEST S₁, S₂ | S₁ & S₂ | Test |
这里是一些跳转语句示例:
| Instruction | Synonym | Jump condition | Description |
|---|---|---|---|
| jmp Label | 1 | Direct jump 例:jmp 0x400123 直接跳转到具体地址 |
|
| jmp *Operand | 1 | Indirect jump 例:jmp *%rax 跳转目标在运行时才能确定 |
|
| je Label | jz | ZF | Equal / zero |
| js Label | SF | Negative | |
| jg Label | jnle | ~(SF ^ OF) & ~ZF | Greater (signed >) |
| jge Label | jnl | ~(SF ^ OF) | Greater or equal (signed >=) |
switch
要注意的是,switch 和 if 的汇编有本质区别。switch 基于跳转表(类似哈希表),它先把 case 同时增减一个值来让最小的 case 变为 0,然后建立跳转表,并根据 case 的值来计算合适的跳转地址。
以这个 C 代码为例,它可能被编译成下面的汇编代码:
1 | switch(n) { |
1 | cmpl $2, %eax # 检查是否超出范围(>2), 这里%eax = x-1, |
函数和栈
啊哈哈,我们又要讨论寄存器了。还记得 %rsp 吗?它就是存储栈指针的寄存器。下图左边是栈的结构,右边是寄存器:
那么,栈和函数有什么关系呢?
借助栈来控制转移
栈的第一个作用是“passing control“,即控制转移。
调用函数(callq)本质上就是让程序计数器跳转(jmp)到了函数所在的汇编地址,并把调用完成后应该执行的指令地址压入栈中(pushq)。而函数返回(retq)本质上就是把调用完成后应该执行的指令地址 pop 出来(popq),并跳转回去(jmp)。
借助栈来存储数据
栈的另一个作用是存储数据。
在函数被调用时,栈指针会移动并为这个函数分配一些栈空间用于存储寄存器的值、存储本地变量、传入的参数之类的东西。我们一个一个解释。
寄存器:在上图的右边可以看到有 caller saved 和 callee saved 的寄存器,标注 caller saved 的寄存器由调用者负责保存,标注 callee saved 的寄存器由被调用者负责保存。比如说,在被调用的函数返回时,被调用者要确保 callee saved 的寄存器和调用前没有区别。
本地变量:有时候寄存器不足以保存所有本地变量,就要放到栈中。
传入的参数:参数确实可以存在寄存器中,但有时候寄存器不够存,也就只能放到栈中了。我们可以用类似 movl -4(%rsp), %edx 的指令来获取传入的参数。
1 | 高地址 |
对了,根据上面的描述,递归就成了自然涌现出的结果,真神奇!
数据结构
我们来聊聊 array、struct、union 都是怎么表示在内存中的。
array 和寻址
先说 Array,二维 array 如下图:
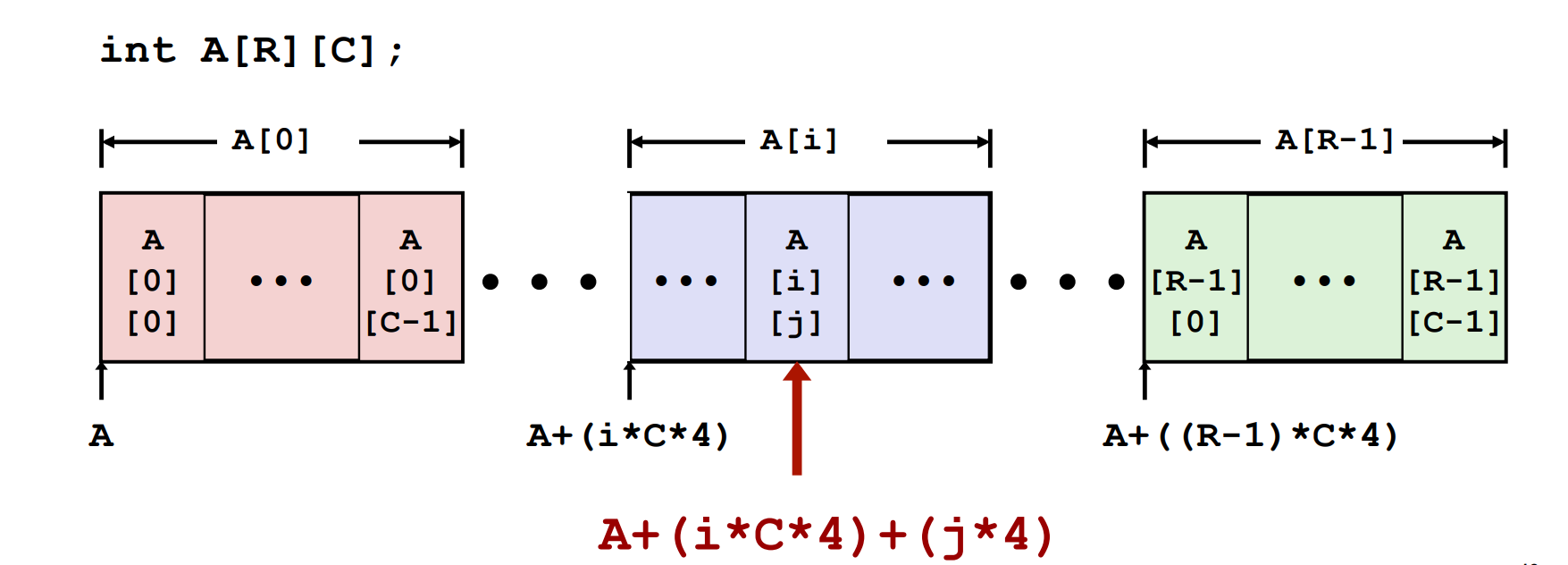
简单易懂。假设我们有 T A[R][C],那么&D[i][j] = x0 + L(C * i + j). 其中 x0 为数组的起始地址,L 是 sizeof(T). 编译器在寻址时也就是这么做的。不过编译器会做一些聪明的优化来避免乘法,比如用 leaq 来加快计算:
1 | # A in %rdi, i in %rsi, and j in %rdx |
struct 和对齐
再来聊聊 struct,看看这张图就差不多了:
1 | struct rec { |
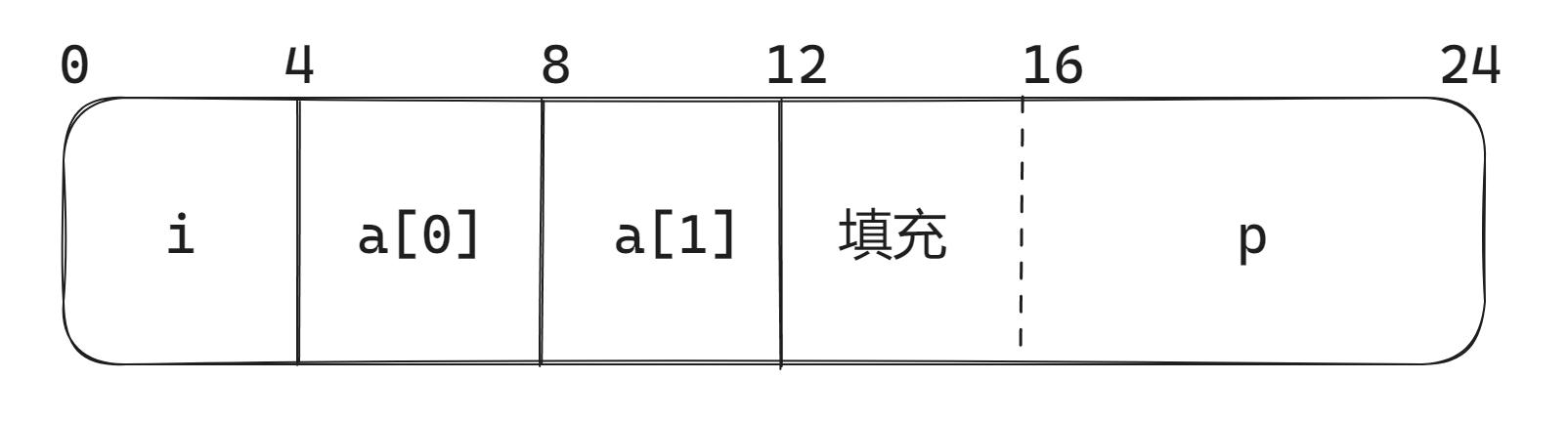
上图中,12 到 16 的“填充”是出于数据对齐的需要,对齐原则是——任何 K 字节的基本对象的地址必须是 K 的倍数。
| K | type |
|---|---|
| 1 | char |
| 2 | short |
| 4 | int, float |
| 8 | long, double, char * |
union
union 允许我们用不同方式解释同一段位表示,常用于节省内存。
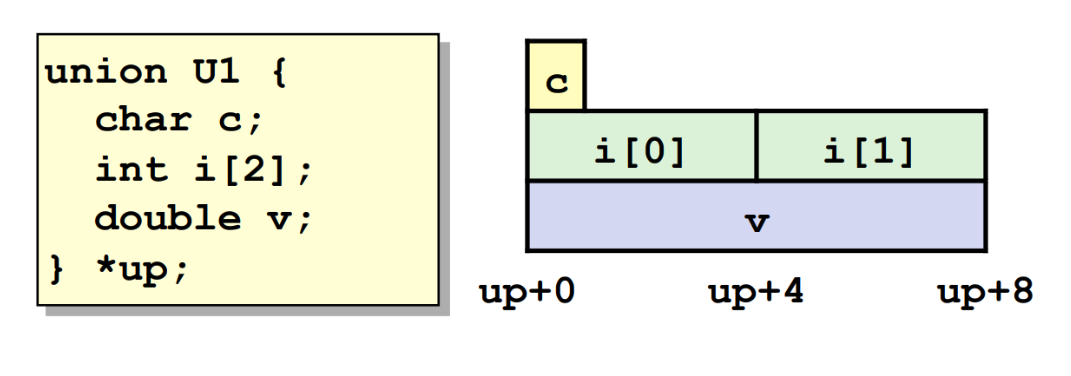
最常见的应用是,union 中的东西互斥,比如实现比较基础的动态类型:
1 | struct DynamicValue { |
变长栈帧和%rbp
有时我们会用到长度不定的数组,比如
1 | int coolArr(int n) { |
这时我们在调用函数前是无法确定要为函数分配多少栈空间的,编译出来的函数会形如
1 | collArr: |
编译器会用 %rbp 作为基指针(base pointer)来记录进入函数前的栈指针位置,并在返回时复位 %rsp 和 %rbp 的状态。
攻击与防御
攻击
最常见的攻击是缓冲区溢出攻击,CSAPP 里讲了栈溢出攻击,具体可以看看 attacklab. 这可以分为植入恶意代码和 ROP 攻击。
防御
对栈溢出的防御手段主要有栈破坏检测、栈随机化、限制可执行代码区域。
最有效的手段是栈破坏检测,只要你破坏不了栈,自然就没办法攻击了。常用的手段是金丝雀值,即在调用允许用户修改栈的函数时,在栈里放一个随机值,然后在函数返回时判断这个值是否被改变。
栈随机化是指每次运行代码时,栈的地址都不一样。
限制可执行代码区域可以防御植入恶意代码到栈里,只要不允许执行栈里的代码就行了。