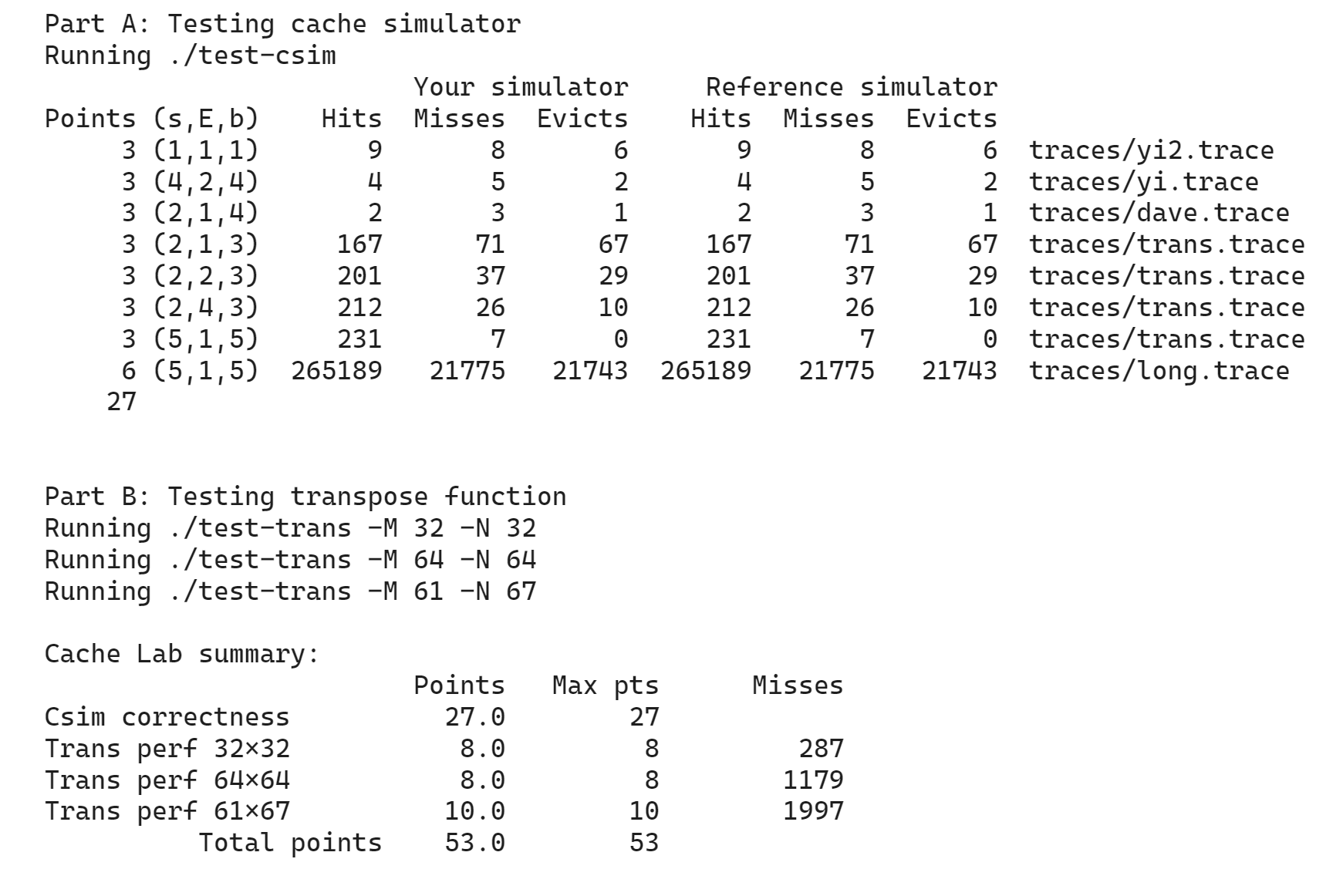
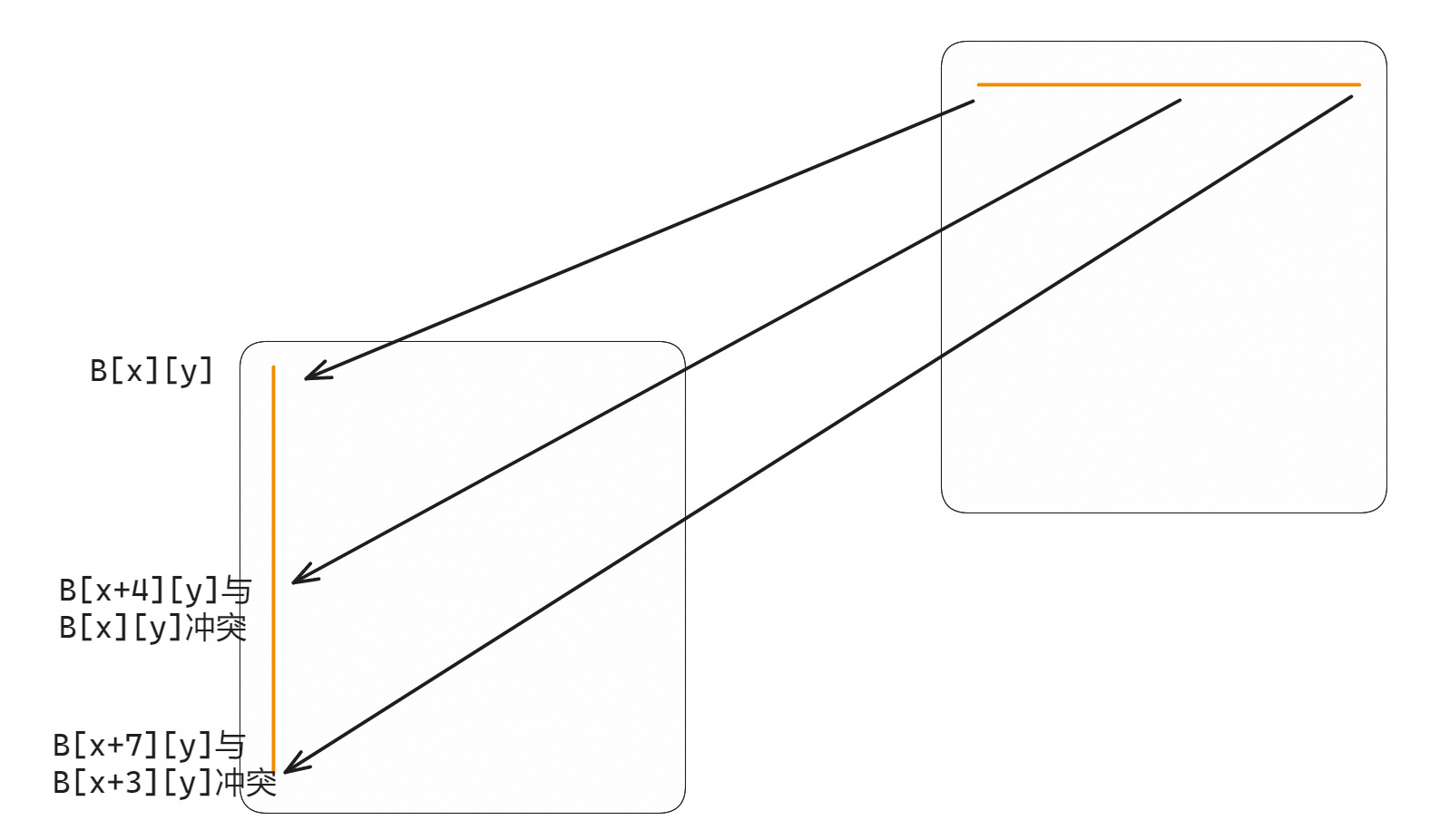
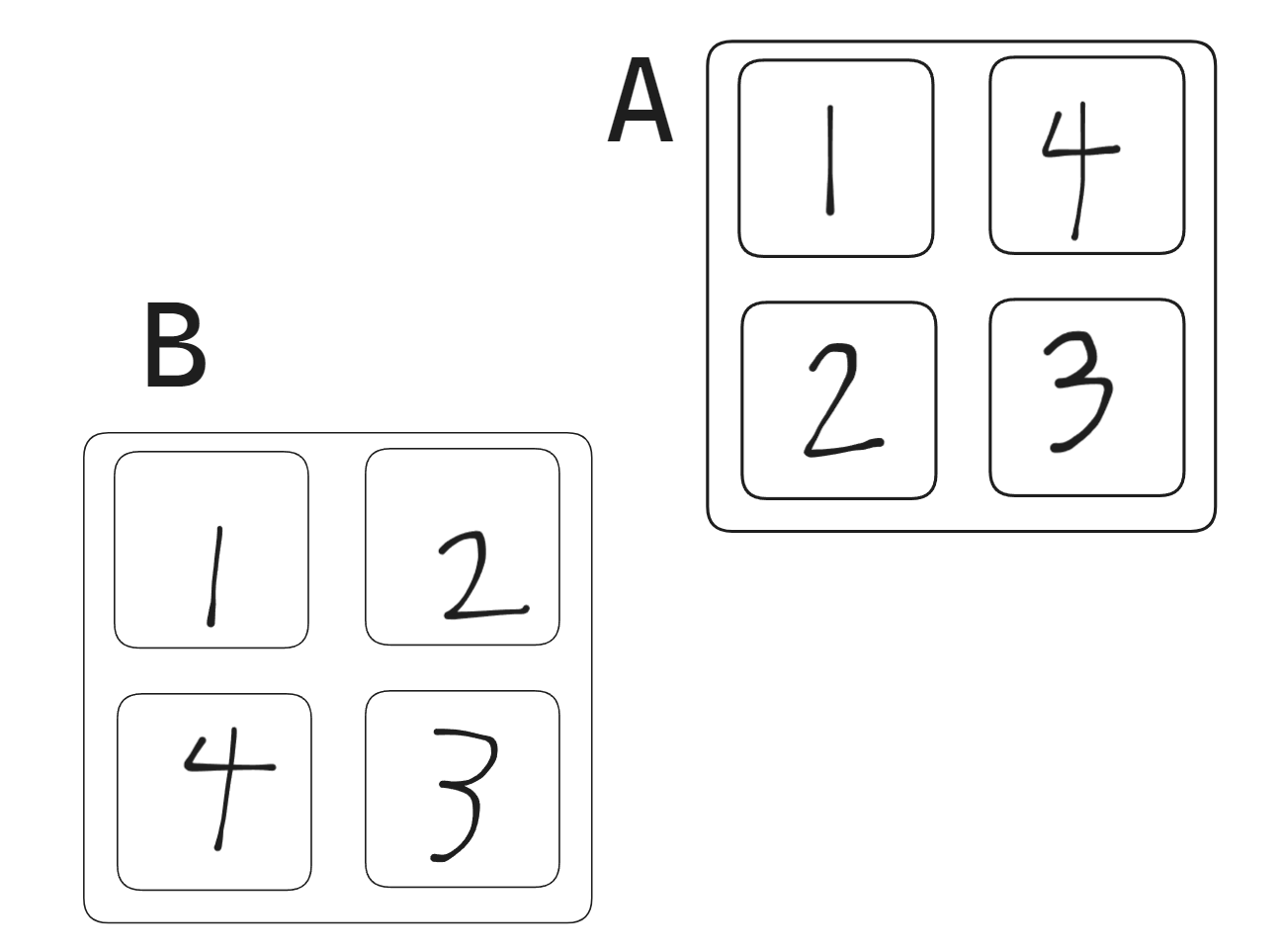
part A 不难,正常模拟一遍就好。由于 handout 里说,“you should assume that memory accesses are aligned properly, such that a single memory access never crosses block boundaries”,所以对每行记录,我们只要考虑其指令类型和地址即可,不必考虑操作大小。我使用了这样的数据结构:
1 2 3 4 5 6 7 8 9 10 11
typedefstruct { int valid; unsignedlong lineTag; int lruCount; // 记录上一次访问到现在的时间 } CacheLine;
voidtranspose_submit(int M, int N, int A[N][M], int B[M][N]) { int blockSize = 8; int rowBlock, colBlock, i, j; // 向上取整, 计算出总 block 数. // 可能会含有不是正方形的 block int rowBlocks = (N + blockSize - 1) / blockSize; int colBlocks = (M + blockSize - 1) / blockSize; int tmp[blockSize][blockSize]; // cachelab不允许开数组
for (rowBlock = 0; rowBlock < rowBlocks; rowBlock++) { for (colBlock = 0; colBlock < colBlocks; colBlock++) { for (i = rowBlock * blockSize; i < (rowBlock + 1) * blockSize && i < N; i++) { for (j = colBlock * blockSize; j < (colBlock + 1) * blockSize && j < M; j++) { tmp[j - colBlock * blockSize][i - rowBlock * blockSize] = A[i][j]; } } for (j = colBlock * blockSize; j < (colBlock + 1) * blockSize && j < M; j++) { for (i = rowBlock * blockSize; i < (rowBlock + 1) * blockSize && i < N; i++) { B[j][i] = tmp[j - colBlock * blockSize][i - rowBlock * blockSize]; } } } } }
结果很不错:
Cache Lab summary: Points Max pts Misses Trans perf 32x32 8.0 8 261 Trans perf 64x64 8.0 8 1029 Trans perf 61x67 10.0 10 1725
voidtranspose_submit_64x64(int M, int N, int A[N][M], int B[M][N]) { int blockSize = 8; int rowBlock, colBlock, i, j; int rowBlocks = (N + blockSize - 1) / blockSize; int colBlocks = (M + blockSize - 1) / blockSize; int tmp0, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7;
voidtranspose_submit(int M, int N, int A[N][M], int B[M][N]) { int blockRow = 16; // 块的行数 int blockCol = 8; // 块的列数 int rowBlock, colBlock, i, j; // 向上取整, 计算出总 block 数 int rowBlocks = (N + blockRow - 1) / blockRow; int colBlocks = (M + blockCol - 1) / blockCol;
int tmp0, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7;
for (rowBlock = 0; rowBlock < rowBlocks; rowBlock++) { for (colBlock = 0; colBlock < colBlocks; colBlock++) { for (i = rowBlock * blockRow; i < (rowBlock + 1) * blockRow && i < N; i++) { // 展开j循环,每次处理8个元素 j = colBlock * blockCol; if (j < M) tmp0 = A[i][j]; if (j + 1 < M) tmp1 = A[i][j + 1]; if (j + 2 < M) tmp2 = A[i][j + 2]; if (j + 3 < M) tmp3 = A[i][j + 3]; if (j + 4 < M) tmp4 = A[i][j + 4]; if (j + 5 < M) tmp5 = A[i][j + 5]; if (j + 6 < M) tmp6 = A[i][j + 6]; if (j + 7 < M) tmp7 = A[i][j + 7];
// 写入B矩阵 if (j < M) B[j][i] = tmp0; if (j + 1 < M) B[j + 1][i] = tmp1; if (j + 2 < M) B[j + 2][i] = tmp2; if (j + 3 < M) B[j + 3][i] = tmp3; if (j + 4 < M) B[j + 4][i] = tmp4; if (j + 5 < M) B[j + 5][i] = tmp5; if (j + 6 < M) B[j + 6][i] = tmp6; if (j + 7 < M) B[j + 7][i] = tmp7; } } } }