先放一个最终结果在这里
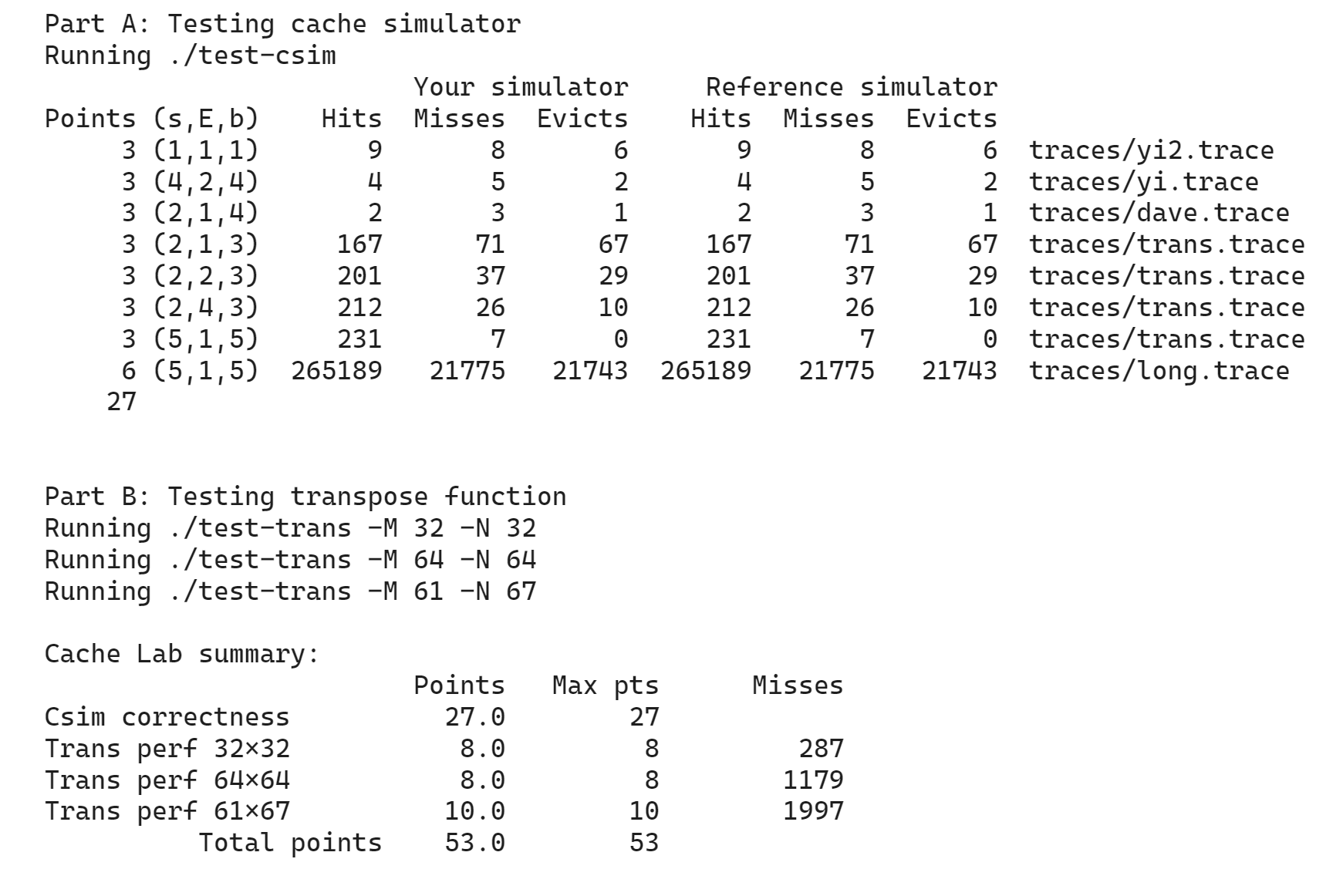
Part A 模拟 cache
用时 3h.
一开始因为 16 进制踩了坑。我第一个看的 trace 文件是 yi.trace,我把里面的地址当成了十进制,分析了半天总感觉不对,后来惊醒这是十六进制。
part A 不难,正常模拟一遍就好。由于 handout 里说,“you should assume that memory accesses are aligned properly, such that a single memory access never crosses block boundaries”,所以对每行记录,我们只要考虑其指令类型和地址即可,不必考虑操作大小。我使用了这样的数据结构:
typedef struct {
int valid;
unsigned long lineTag;
int lruCount; // 记录上一次访问到现在的时间
} CacheLine;
typedef struct {
CacheLine *lines;
} CacheSet;
CacheSet *sets = malloc((1 << s)* sizeof(CacheSet));在核心循环里,对某个给定的 set,我们在遍历过程中从前往后填充每个 set 的 line,思路如下:
对每个地址,用位运算得到其 setIdx 和 tag,然后找到对应的 set,遍历里面的所有 line. 如果找到了空 line,直接填充进去;如果找到了对应的 tag,就 hit 了;如果没找到对应 tag,说明需要驱逐某个 line,找到 lru 最大的 line(即最久没有访问过的 line)并把它换掉即可。
注意正确更新遍历的 set 里的每个 line 的 lruCount.
用下面的位运算就能得到 setIdx 和 tag:
unsigned long mask = -1;
mask = ~(mask << s); // 000...11 (s 个 1)
unsigned long setIdx = (address >> b) & mask;
unsigned long tag = address >> (b + s);还有一个小 trick 是可以用这样的写法来简化代码,毕竟我们并不关心操作在类型上的差异,只关心操作的地址:
switch (operation) {
case 'M':
// M = L + S, 其 'S' 总会命中
hits++;
// fall through
case 'L':
// fall through
case 'S':
// 真正的工作
}Part B
用时 7 h,拼尽全力也只能把 64x64 拿到 1411 miss,上网找了找别人的思路,最后得到了 1179 miss. 最后结果如下:
Points Max pts Misses
Trans perf 32x32 8.0 8 287
Trans perf 64x64 8.0 8 1179
Trans perf 61x67 10.0 10 1997
我参考的文章是这篇: CSAPP - Cache Lab 的更(最)优秀的解法 - 知乎,作者直接拿到了 64x64 的理论最优解,非常强大。不过我没有在对角线上做微调,而是只参考了作者对一般块的读写顺序。
我的三个转置都没有特别考虑对角线的情况。一方面是因为嫌麻烦,另一方面是因为我觉得这种“两个内存块位置恰好差 2 的幂次导致缓存抖动”的事情太特殊,所以没额外处理。
分块大小的确定
首先,分块优化是一定要做的。但分成多大的块呢?最朴素的想法是,我们希望块尽可能大来装满 cache,但不要太大以至于 cache 装不下。
我们有 $2^5 = 32$ 个 sets,每个 set 一个 line,每个 line 存 8 个 int,也就是说,我们最多能存 $32 \times 8 = 256 = 2^8$ 个 int. 我们希望同时把 A 的块和 B 的块放到 cache 中,两个块大小应当相同,所以每个块可以放 $256/2 = 128$ 个 int. 128 不是完全平方数,所以我们可以分块成 8x8.
初版代码
回到之前的 8x8 分块的讨论上来。总之,我写出了我的初版代码。思路就是分块,然后把 A 的块存到 tmp 数组里,然后复制到 B 里。为什么要用 tmp 做中转呢?答案是为了避免缓存冲突:
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int blockSize = 8;
int rowBlock, colBlock, i, j;
// 向上取整, 计算出总 block 数.
// 可能会含有不是正方形的 block
int rowBlocks = (N + blockSize - 1) / blockSize;
int colBlocks = (M + blockSize - 1) / blockSize;
int tmp[blockSize][blockSize]; // cachelab不允许开数组
for (rowBlock = 0; rowBlock < rowBlocks; rowBlock++) {
for (colBlock = 0; colBlock < colBlocks; colBlock++) {
for (i = rowBlock * blockSize; i < (rowBlock + 1) * blockSize && i < N; i++) {
for (j = colBlock * blockSize; j < (colBlock + 1) * blockSize && j < M; j++) {
tmp[j - colBlock * blockSize][i - rowBlock * blockSize] = A[i][j];
}
}
for (j = colBlock * blockSize; j < (colBlock + 1) * blockSize && j < M; j++) {
for (i = rowBlock * blockSize; i < (rowBlock + 1) * blockSize && i < N; i++) {
B[j][i] = tmp[j - colBlock * blockSize][i - rowBlock * blockSize];
}
}
}
}
}结果很不错:
Cache Lab summary:
Points Max pts Misses
Trans perf 32x32 8.0 8 261
Trans perf 64x64 8.0 8 1029
Trans perf 61x67 10.0 10 1725
正当我觉得 cachelab 不过如此的时候,忽然发现 handout 里写了不允许开数组(哈哈,你想得到的 cmu 老师想不到吗),于是被迫手动展开了 j 循环,使用 8 个变量来读取每行的值。这就得到了下面的结果:
Cache Lab summary:
Points Max pts Misses
Trans perf 32x32 8.0 8 287
Trans perf 64x64 0.0 8 4611
Trans perf 61x67 10.0 10 1997
也还算不错吧,毕竟 32x32 和 61x67 都满分了。唯一的问题是 64x64 的性能奇差无比。
分析 64x64 矩阵的 miss 次数
这时候就要理论分析了。对 64x64 的矩阵,按我们之前的做法,每个 8x8 的块大约发生了多少次 miss 呢?
答案是 72 次。A 提供了 8 次 miss,B 提供了 64 次 miss
验证一下结果对不对:64x64 的矩阵共有 64 个 8x8 的块,64 个块每个块 72 次 miss,总计约 $64 \times 72=4608$ 次 miss,和结果 4611 次 miss 相差无几。
这个 miss 是怎么算出来的呢?让我们看看下图:
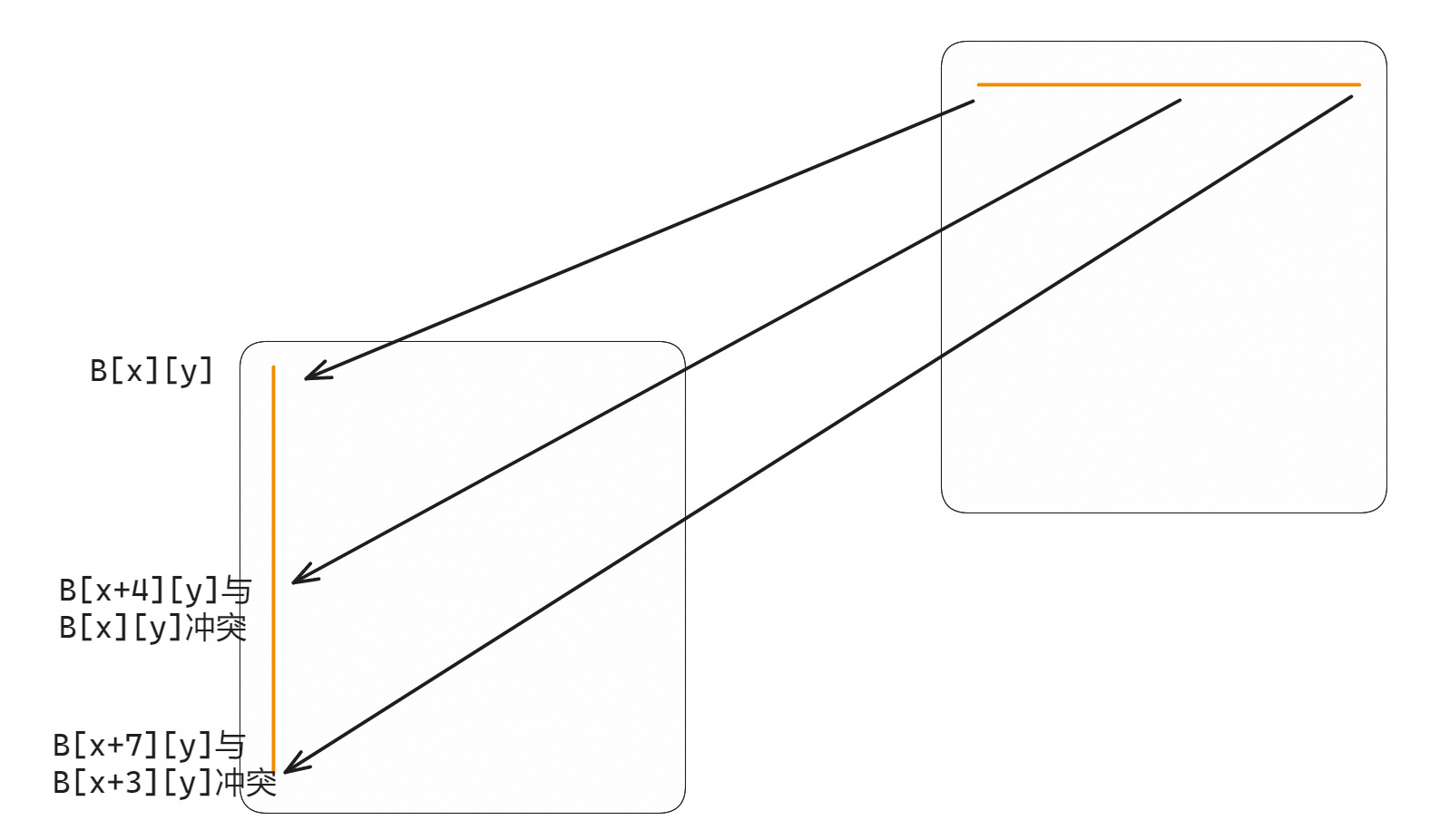
对 64x64 的矩阵来说,B[x][y] 和 B[x+4][y] 的 setIdx 相同,这就导致我们之前的方法不断驱逐旧 line. 定量地说,每读 A 的块的一行,大约是 1 个 miss,A 的块共有 8 行,所以 A 的每个块提供 8 次 miss;每对 B 的块写入一个值,都驱逐了一次旧 line(因为 B[x+4][y] 会驱逐 B[x][y]),所以 B 的每个块提供 64 次 miss.
之后的工作就是找到方法来避免这种驱逐了。
对 64x64 矩阵的第一次优化——1699
一开始我的思路是直接用 4x4 的块,这确实有不小优化,但离满分还很远。读者可以试着做一个理论分析看看 4x4 的结果大概是多少 miss。我分析出来会得到 1536 个 miss,实际结果是 1699 个 miss,也差不多吧。
好吧,这个理论分析看起来值得详细讲解一下。不过在写之前,希望读者自己分析一下,看看得到的结果是不是 2048,并想想哪里出错了:
如果块的大小是 4x4,每个块发生 4 次 miss,每个矩阵 256 个块,一共 2048 次 miss,看起来很合理。但这是理论最优解,为什么理论最优(2048)比实际结果(1699)还差呢?难道说数学的大厦崩塌了?
并非如此。事实上,在我们把某个 4x4 的块放入 cache 时,我们也同时把它的右边的那个 4x4 的块放入了 cache。这是因为 cache 的每个 line 能装 8 个 int.
也就是说,我们可以认为我们实际上是在处理 4x8 的块。对每个 4x8 的块,A 提供了 4 次 miss,B 提供了 8 次 miss,总计 $64 4 + 64 8 = 1536$ 次 miss.
对 64x64 矩阵的第二次优化——1411
分析了那么多,还是没拿到满分。我的后续思路是把 8x8 的块再分成四个小块,并按下面的顺序来写入 B:
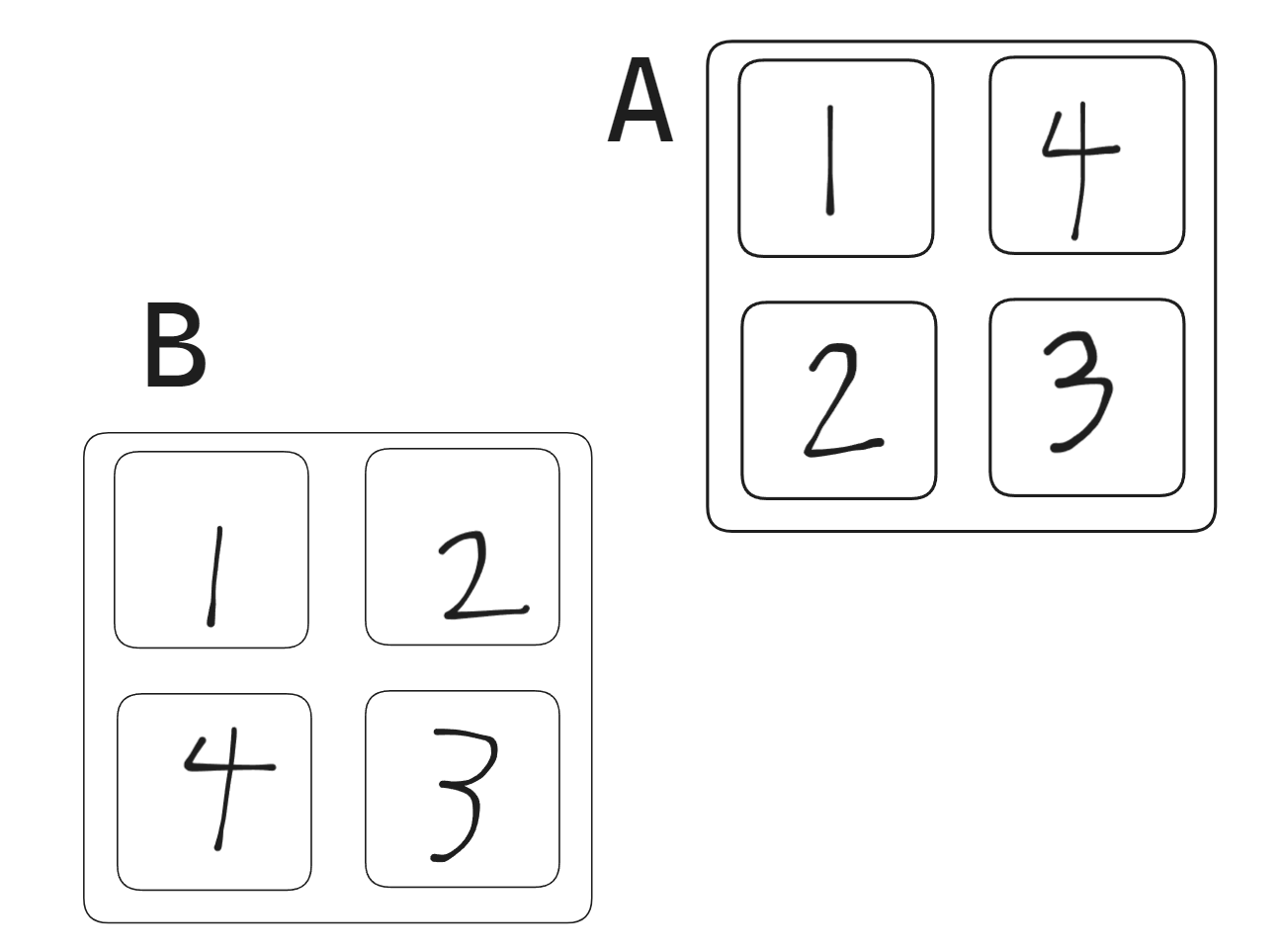
理论分析一下,把 A1 写入 B1 时,A miss 4 次,B miss 4 次;
把 A2 写入 B2 时,A miss 4 次,B 没有 miss(因为写入 B1 时把 B2 放进了 cache);
把 A3 写入 B3 时,A 没有 miss,B miss 4 次;(因为读 A2 时把 A3 放入了 cache);
把 A4 写入 B4 时,A miss 4 次,B 没有 miss(因为写入 B3 时把 B4 放进了 cache)
总计 20 次 miss,理论最优解 1280,实际结果 1411,我猜问题出在对角线上,我也懒得在这个基础上继续优化了。优化对角线这种事情看起来就很麻烦,而且感觉现实里几乎不会遇见这种情况。
对 64x64 矩阵的第二次优化——1179
没什么好说的,直接看 CSAPP - Cache Lab 的更(最)优秀的解法 - 知乎 和代码吧。这篇文章的作者拿到了 64x64 的理论最优解,非常强大。不过我没有在对角线上做微调,而是只参考了作者对一般块的读写顺序。
void transpose_submit_64x64(int M, int N, int A[N][M], int B[M][N])
{
int blockSize = 8;
int rowBlock, colBlock, i, j;
int rowBlocks = (N + blockSize - 1) / blockSize;
int colBlocks = (M + blockSize - 1) / blockSize;
int tmp0, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7;
for (rowBlock = 0; rowBlock < rowBlocks; rowBlock++) {
for (colBlock = 0; colBlock < colBlocks; colBlock++) {
// A上
for (i = rowBlock * blockSize; i < rowBlock * blockSize + blockSize / 2 && i < N; i++) {
// 读取A的一行
tmp0 = A[i][colBlock * blockSize];
tmp1 = A[i][colBlock * blockSize + 1];
tmp2 = A[i][colBlock * blockSize + 2];
tmp3 = A[i][colBlock * blockSize + 3];
tmp4 = A[i][colBlock * blockSize + 4];
tmp5 = A[i][colBlock * blockSize + 5];
tmp6 = A[i][colBlock * blockSize + 6];
tmp7 = A[i][colBlock * blockSize + 7];
// 填充B左上
B[colBlock * blockSize][i] = tmp0;
B[colBlock * blockSize + 1][i] = tmp1;
B[colBlock * blockSize + 2][i] = tmp2;
B[colBlock * blockSize + 3][i] = tmp3;
// 填充B右上, 这一部分未来会被放到B左下
B[colBlock * blockSize][i + blockSize / 2] = tmp4;
B[colBlock * blockSize + 1][i + blockSize / 2] = tmp5;
B[colBlock * blockSize + 2][i + blockSize / 2] = tmp6;
B[colBlock * blockSize + 3][i + blockSize / 2] = tmp7;
}
// A左下, 注意这里按列遍历
for (j = colBlock * blockSize; j < colBlock * blockSize + blockSize / 2 && j < M; j++) {
// 读取 A 的左下小块的一列
tmp0 = A[rowBlock * blockSize + blockSize / 2][j];
tmp1 = A[rowBlock * blockSize + blockSize / 2 + 1][j];
tmp2 = A[rowBlock * blockSize + blockSize / 2 + 2][j];
tmp3 = A[rowBlock * blockSize + blockSize / 2 + 3][j];
// 读取 B 的右上小块的一行
tmp4 = B[j][rowBlock * blockSize + blockSize / 2];
tmp5 = B[j][rowBlock * blockSize + blockSize / 2 + 1];
tmp6 = B[j][rowBlock * blockSize + blockSize / 2 + 2];
tmp7 = B[j][rowBlock * blockSize + blockSize / 2 + 3];
// 把从 A 左下读到的内容写到 B 右上
B[j][rowBlock * blockSize + blockSize / 2] = tmp0;
B[j][rowBlock * blockSize + blockSize / 2 + 1] = tmp1;
B[j][rowBlock * blockSize + blockSize / 2 + 2] = tmp2;
B[j][rowBlock * blockSize + blockSize / 2 + 3] = tmp3;
// 把 B 右上的内容写到 B 左下
B[j + blockSize / 2][rowBlock * blockSize] = tmp4;
B[j + blockSize / 2][rowBlock * blockSize + 1] = tmp5;
B[j + blockSize / 2][rowBlock * blockSize + 2] = tmp6;
B[j + blockSize / 2][rowBlock * blockSize + 3] = tmp7;
}
// A右下
for (i = rowBlock * blockSize + blockSize / 2; i < (rowBlock + 1) * blockSize && i < N; i++) {
// 读取A的一行
tmp0 = A[i][colBlock * blockSize + blockSize / 2];
tmp1 = A[i][colBlock * blockSize + blockSize / 2 + 1];
tmp2 = A[i][colBlock * blockSize + blockSize / 2 + 2];
tmp3 = A[i][colBlock * blockSize + blockSize / 2 + 3];
// 填充B
B[colBlock * blockSize + blockSize / 2][i] = tmp0;
B[colBlock * blockSize + blockSize / 2 + 1][i] = tmp1;
B[colBlock * blockSize + blockSize / 2 + 2][i] = tmp2;
B[colBlock * blockSize + blockSize / 2 + 3][i] = tmp3;
}
}
}
}Future work
写文章的时候突然想到我们似乎可以分长方形的 16x8 的块,因为 $1682 = 256$ 可以完全填满 cache. 简单写了下代码得到了下面的结果:
[16x8]
Points Max pts Misses
Trans perf 32x32 8.0 8 287
Trans perf 61x67 10.0 10 1811
看起来效果出乎意料地不错?甚至比我的 8x8 分块效果更好。这里没有放进来 64x64 转置的结果,因为我没有做分小块的优化。所以说,这种方法说不定还有不小探索空间?
下面是我的 8x8 分块的结果,可以用来和上面的结果做比较。两个代码都只用了简单的分块和 8 个 tmp 变量,没有额外优化。
[8x8]
Points Max pts Misses
Trans perf 32x32 8.0 8 287
Trans perf 61x67 10.0 10 1997
这里是我使用的 16x8 的分块代码:
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int blockRow = 16; // 块的行数
int blockCol = 8; // 块的列数
int rowBlock, colBlock, i, j;
// 向上取整, 计算出总 block 数
int rowBlocks = (N + blockRow - 1) / blockRow;
int colBlocks = (M + blockCol - 1) / blockCol;
int tmp0, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7;
for (rowBlock = 0; rowBlock < rowBlocks; rowBlock++) {
for (colBlock = 0; colBlock < colBlocks; colBlock++) {
for (i = rowBlock * blockRow; i < (rowBlock + 1) * blockRow && i < N; i++) {
// 展开j循环,每次处理8个元素
j = colBlock * blockCol;
if (j < M) tmp0 = A[i][j];
if (j + 1 < M) tmp1 = A[i][j + 1];
if (j + 2 < M) tmp2 = A[i][j + 2];
if (j + 3 < M) tmp3 = A[i][j + 3];
if (j + 4 < M) tmp4 = A[i][j + 4];
if (j + 5 < M) tmp5 = A[i][j + 5];
if (j + 6 < M) tmp6 = A[i][j + 6];
if (j + 7 < M) tmp7 = A[i][j + 7];
// 写入B矩阵
if (j < M) B[j][i] = tmp0;
if (j + 1 < M) B[j + 1][i] = tmp1;
if (j + 2 < M) B[j + 2][i] = tmp2;
if (j + 3 < M) B[j + 3][i] = tmp3;
if (j + 4 < M) B[j + 4][i] = tmp4;
if (j + 5 < M) B[j + 5][i] = tmp5;
if (j + 6 < M) B[j + 6][i] = tmp6;
if (j + 7 < M) B[j + 7][i] = tmp7;
}
}
}
}